Review 《How eBPF will solve Service Mesh - Goodbye Sidecars》
Service Mesh (服务网格) 是一个概念,描述了现代云原生应用在通信、可见性和安全性方面的要求。目前这个概念的实现涉及到在每个workload 或 pod 中运行 sidecar 代理。这是一种相当低效的方式。在这篇文章中,我们将探讨一个替代 sidecar 模型的方法,在eBPF的帮助下,提供一个透明的 Service Mesh,在低复杂度下具有很高的效率。
What is Service Mesh?
随着分布式应用的引入,额外的可见性、连接性和安全性要求也浮现出来(have surfaced)。应用程序组件在跨越云和城市边界的不受信任的网络中通信,负载均衡需要理解应用协议,弹性(resiliency)变得至关重要(crucial),安全性必须发展(evolve)到发送者和接收者可以验证彼此身份的模式。在分布式应用的早期,这些要求是通过直接将所需的逻辑嵌入到应用中来解决的。Service Mesh 将这些功能从应用程序中提取出来,作为基础设施的一部分提供给所有应用程序使用,因此不再需要修改每个应用程序。
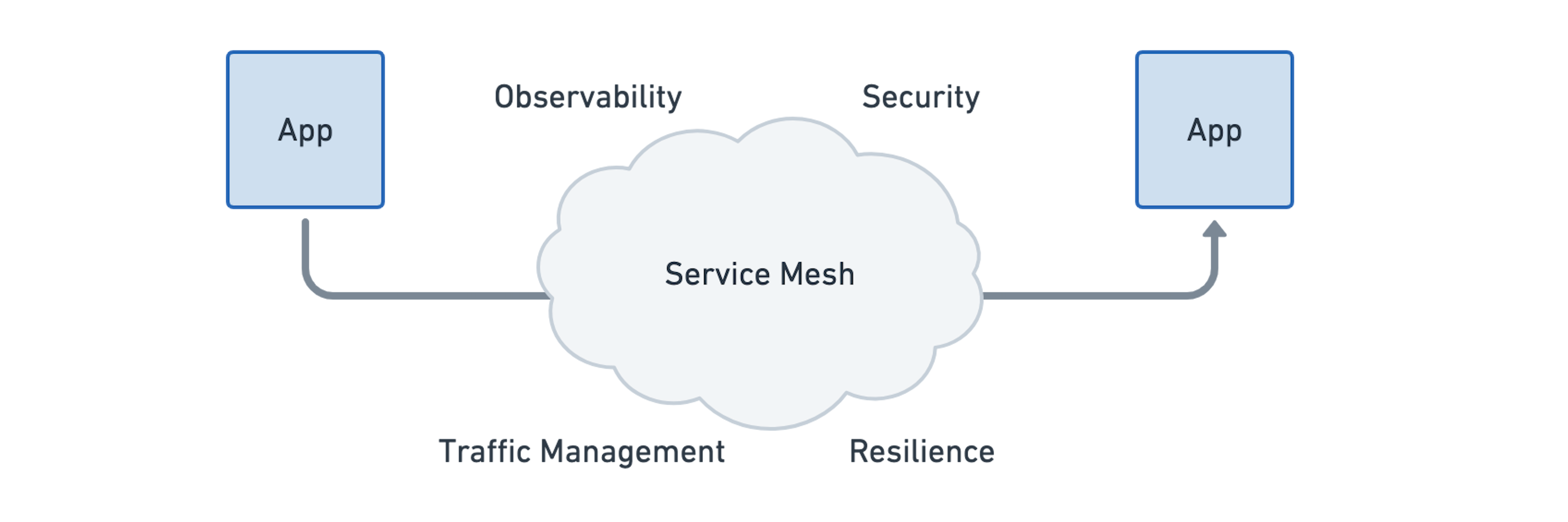
纵观 Service Mesh 今天的特点,可以总结为以下几点:
- 弹性链接: 服务与服务之间的通信必须能够跨越边界,例如云服务,集群和城市。通信必须是弹性且可容错的。
- L7 流量管理: 负载均衡,频率限制器,弹性都必须在 L7 层(能够理解 HTTP, REST, gRPC, WebSocket 等协议)
- 基于身份的安全: 基于网络标识符来实现安全已经不够了,发送和接收服务必须能够基于身份标识认证对方,而不是通过网络标识认证。
- 可观察性和可追踪性: 追踪和指标形式的观察,对于理解,监控,调试应用程序的稳定性,性能和可用性至关重要。
- 透明性:该功能必须以透明的形式提供给应用程序,即不需要改变应用程序的代码。
在早期,Service Mesh 功能通常以库的形式实现,需要网格中的每个应用程序链接到以对应语言编写的库中。同样的事情也在互联网早期发生过,在那些日子里,应用程序需要维护自己的 TCP/IP 栈。就像我们在这篇文章里讨论的一样,Service Mesh 正在发展成为一种内核职责,就像 TCP/IP 网络栈一样。

在今天,Service Mesh 通常是用一种称为 sidecar 模型的架构实现的。这种架构将实现了上述功能的代码封装到4层代理中,然后将应用接收和发送的流量重定向到被称为 sidecar 的代理中。它之所以被成为 Sidecar,是因为每个应用程序都有一个代理,就像摩托车上的挎斗一样。
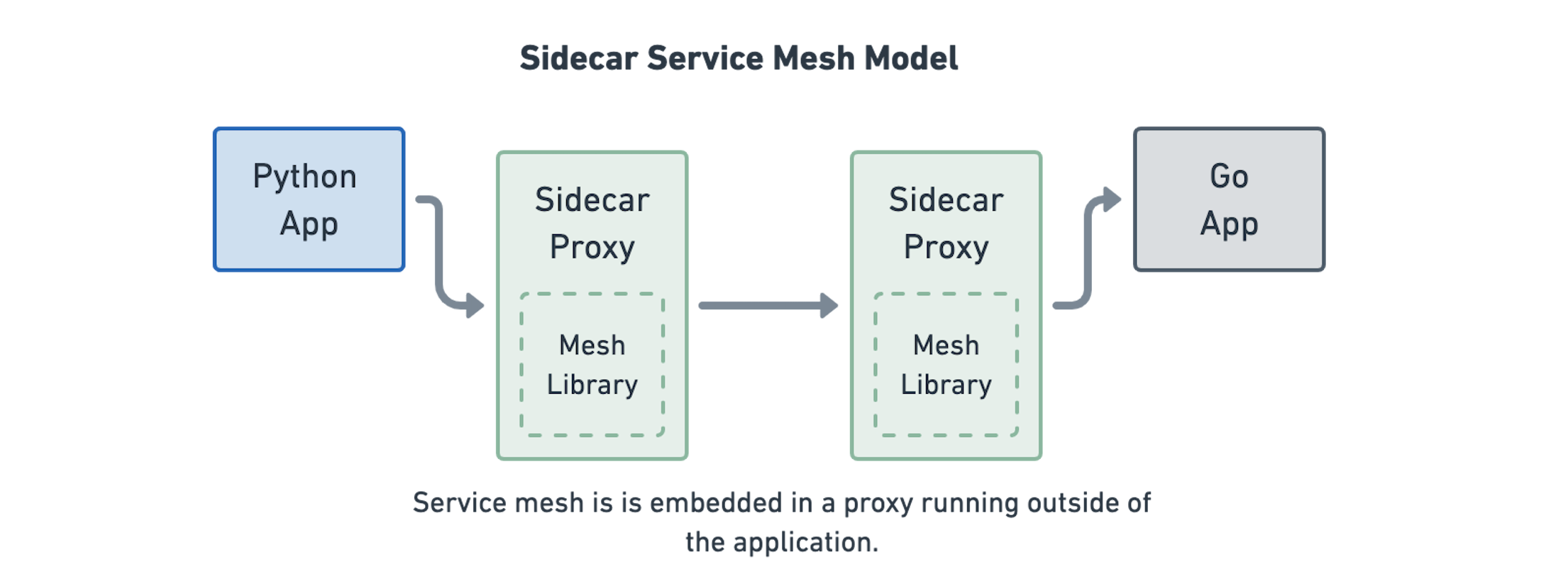
这种架构的优点是应用服务自身不再需要实现 Service Mesh 中的功能。如果许多应用服务使用不同语言编写,或者你运行的服务是一个不可变的第三方应用程序,这种架构就很方便。
这种模型的缺点是有大量的代理,许多额外的网络连接和复杂的重定向逻辑将应用的网络流量送入到代理中。除此之外,四层代理能够传输的网络流量的类型也有限制(四层代理无法理解 HTTP/Thrift 等七层协议)。代理在其能够支持的网络协议上是被限制的。
A history of connectivity moving into the Kernel
几十年来,在应用程序之间提供安全可靠的连接一直是操作系统的责任。你们中的一些人可能还记得早期 Unix 和 Linux 时代的 TCP Wrapper 和 tcpd。它可以被认为是原始的 sidecar ,tcpd 允许用户透明地添加日志,访问控制,主机名验证,欺骗保护功能到应用程序中,而不需要修改应用程序。 它使用了 libwrap 库,而且,在一个有趣的平行与服务网格历史的故事中,这个库也是以前的应用程序提供这些功能的链接对象。tcpd 带来的是能够在不修改现有应用程序的情况下将这些功能透明地添加到现有应用程序中。最终,所有这些功能都进入了 Linux 本身,并以一种更有效,更强大的方式提供给应用程序。今天,这已经演变成了我们熟知的 iptables。
然而,iptables 显然不适合解决现代网络的连接性,安全性和可观察性要求,因为它在网络层面上运行,缺少对应用协议层的任何理解。自然,阻力最小的路径是回到库模型,然后是 sidecar 模式。现在,我们正处于这样一个阶段:为了最佳的透明度、效率性和安全性,在操作系统中原生地支持这种模式是有意义的。

在曾经的 TCPD 时代使用的 连接记录 (connection logging back),现在变成了追踪 (tracing)。在 IP 层的访问控制已经进化成了在应用层的授权(例如使用 JWT 进行授权)。主机名验证已经被更强大的认证所取代,例如双端 TLS 认证。网络负载均衡已经扩展到 L7 层的流量管理功能。HTTP 重试是新的 TCP 重传。过去使用黑洞路由解决的问题今天被称为 熔断(circuit breaking)。这些都不是根本性的新问题,但所需的环境和控制都已经发生了变化。
Extending the Kernel Namespace Concept
Linux 内核已经有一个概念,可以共享相同的功能,并使其对系统上运行的许多应用程序可用。这个概念被称为命名空间,它构成了我们今天所熟知的容器技术的基础。命名空间(内核的概念)存在于各种抽象中,包括文件系统、用户管理,挂载设备,进程,网络等。这就是允许独立的容器用 不同的文件系统视图、不同的用户集存在,以及允许多个容器绑定到同一台主机上的同一个端口。在 cgroups 的帮助下,这个概念得到了扩展,可以对 CPU、内存和网络等资源进行资源管理和有限排序。从云原生应用开发者的角度来看,cgroups 和 资源被紧密地整合到了我们熟知的 “容器” 概念中。
符合逻辑的是,如果我们认为服务网格是操作系统的责任,那么它必须遵循并集成命名空间和 cgroups 的概念。这看起来是这样的:
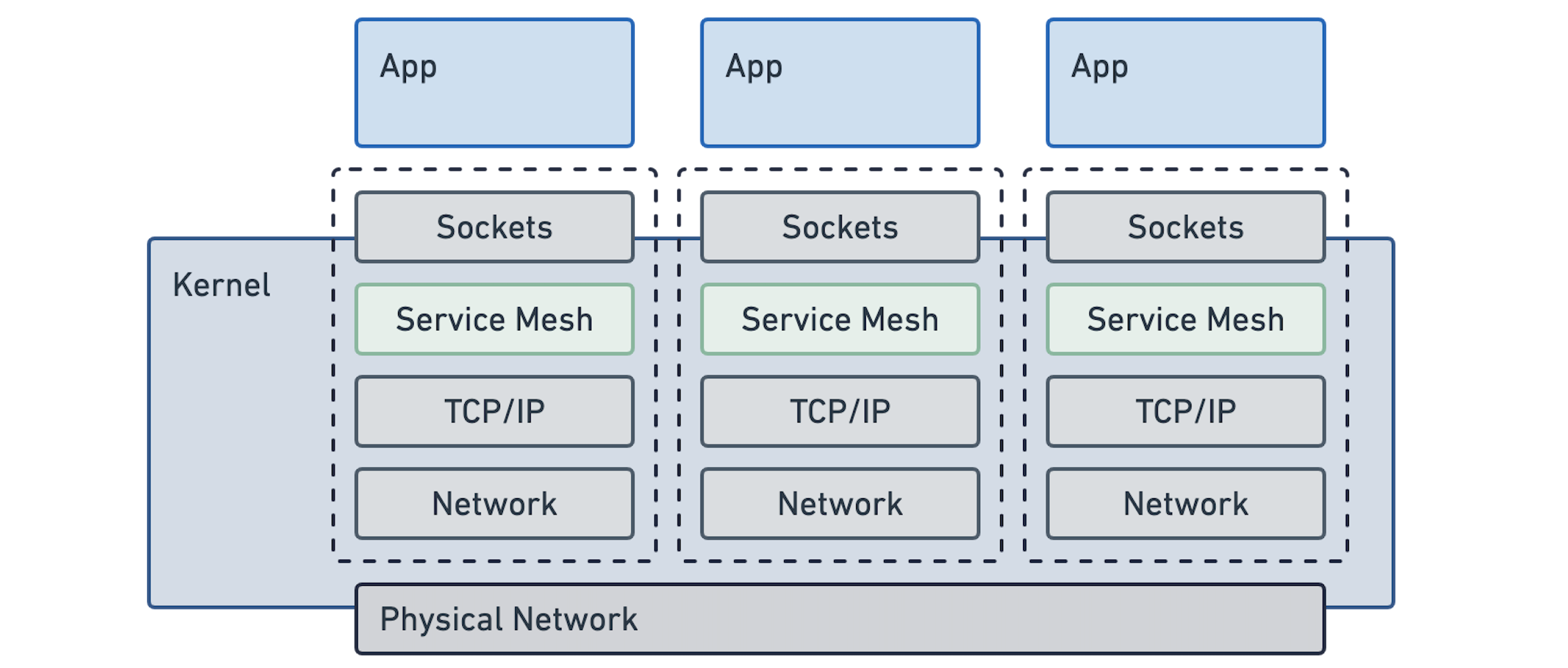
不出所料,这看起来非常自然,而且可能是大多数用户从简单的角度所期望的。应用程序保持不变,它们就像以前一样继续使用网络套接字进行通信。理想的服务网络功能是作为 Linux 的一部分透明地提供的。它就在那里,就像今天的 TCP 一样。
The Cost of Sidecar Injection
如果我们仔细研究一下 sidecar 模型,我们会发现它实际上是在试图模仿这种模型。应用程序继续使用套接字,一切都被塞进 Linux 内核的网络命名空间。然而,这让它比看起来要复杂许多,需要许多额外的步骤来透明地注入 sidecar 代理:
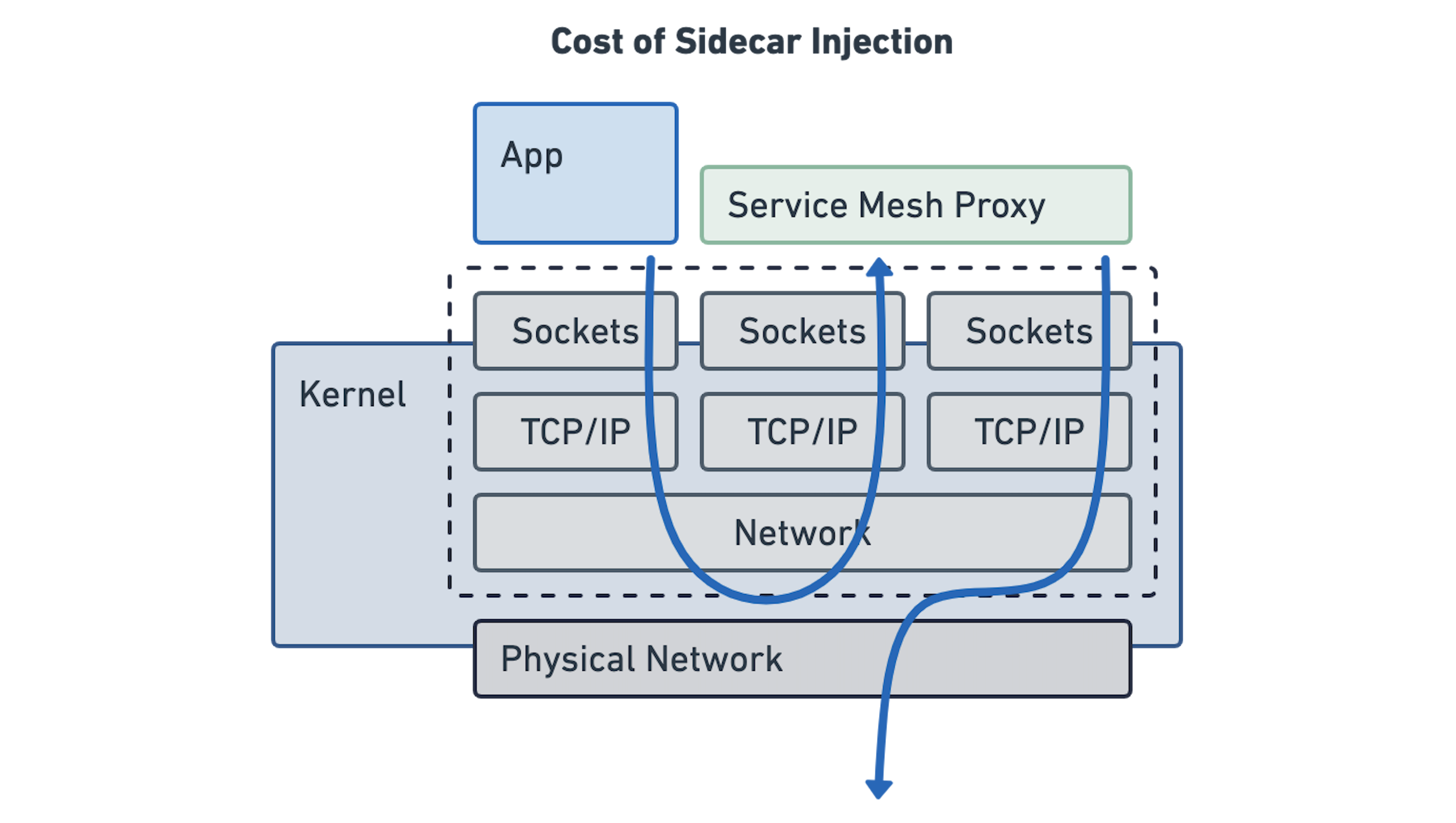
这种额外的复杂性在延迟和额外资源消耗方面付出了巨大的代价。早期的基准测试表明,这让延迟增加了3到4倍,而且所有的代理都需要大量的额外内存。在本文的后面,我们将研究这两点,因为我们将要将它和 eBPF 模型比较。
Unlocking the Kernel Service Mesh with eBPF
为什么我们以前在内核中没有创建一个服务网格?有些人半开玩笑地说,kube-proxy 是最初的服务网格(See We’ve Made Quite A Mesh - Tim Hockin, Google)。这句话是有一定道理的。kube-proxy 是一个很好的例子,说明了 Linux 内核在依靠传统的基于网络的 iptables 功能实现服务网格时,可以达到多么接近。然而,这还不够,L7 的上下文是缺失的。kube-proxy 完全在数据包层面操作,现代应用程序需要 L7 层的流量管理,追踪,认证和额外的可靠性保证。kube-proxy 不能在网络层面上提供这些。
eBPF 改变了这个等式( equation ),它允许动态地扩展 Linux 内核的功能。我们已经使用 eBPF 为 Cilium 构建了一个高效的网络,安全和可观察的数据通路。并将其直接嵌入到 Linux 内核。应用这个相同的概念,我们也可以在内核层面上解决服务网格的需求。事实上,Cilium 已经实现了各种所需的概念,例如基于身份的安全,L3-L7可观察性和授权,加密,负载均衡。缺少的部分 Cilium 正在添加中。在本文的莫问,你会发现如何加入有 Cilium 社区推动的 Cilium 服务网格 beta 项目的细节。
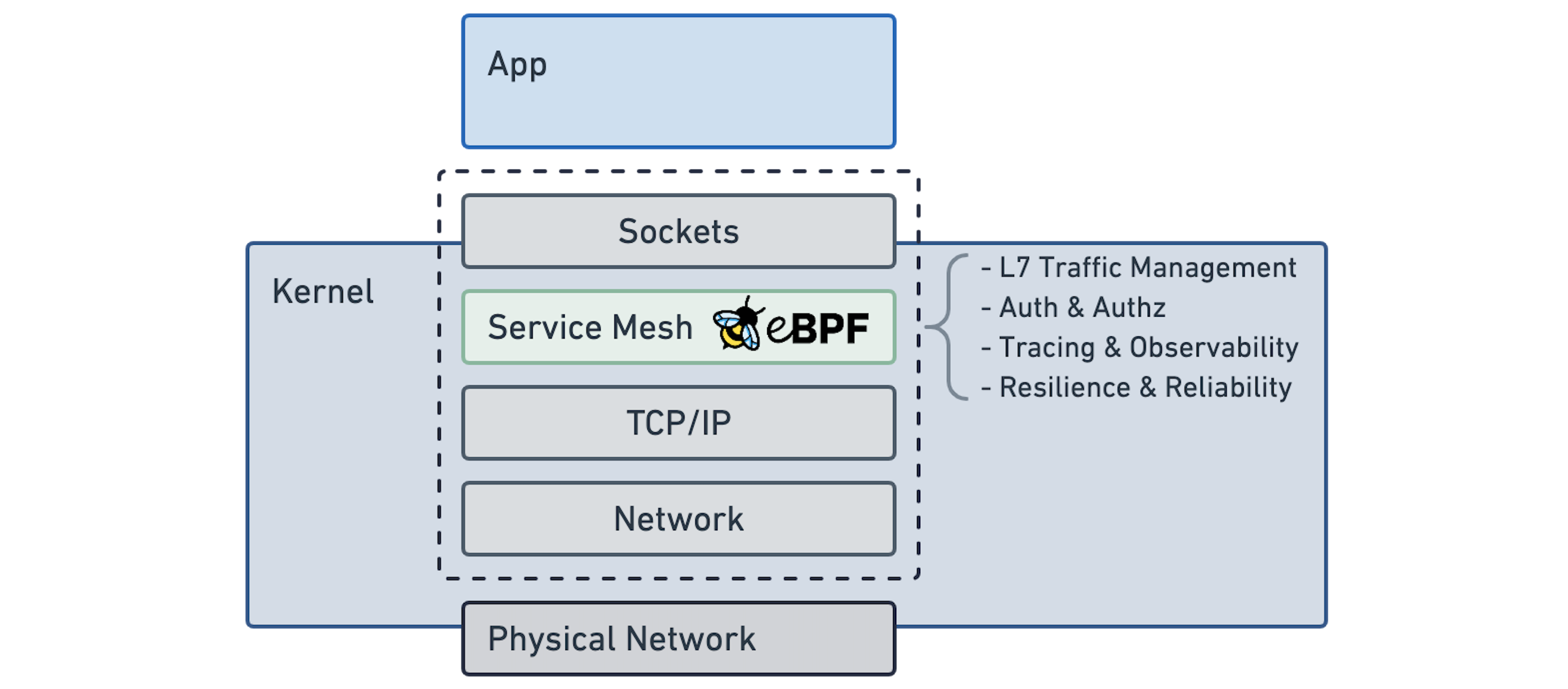
你们中的一些人可能想知道为什么Linux内核社区没有直接解决这些需求。eBPF有一个巨大的优势,eBPF代码可以在运行时插入到现有的Linux内核中,类似于Linux内核模块,但与内核模块不同,它可以以安全和可移植的方式进行。这使得eBPF的实现能够随着服务网状结构社区的发展而继续发展。新的内核版本需要几年时间才能进入用户手中。eBPF是一项关键技术,它使Linux内核能够跟上快速发展的云原生技术栈。
eBPF-based L7 Tracing & Metrics without Sidecars
让我们以 L7 层的追踪和指标可观察性作为一个具体的例子,来说明基于 eBPF 的服务网格在保持低延迟和保持低可观察成本上有巨大的作用。应用程序团队依靠应用程序的可见性和可监控作为基本要求,这包括了请求跟踪,HTTP 响应率,服务延迟信息等。然而,这些观察不应该有明显的成本(延迟,复杂性,资源等成本)。
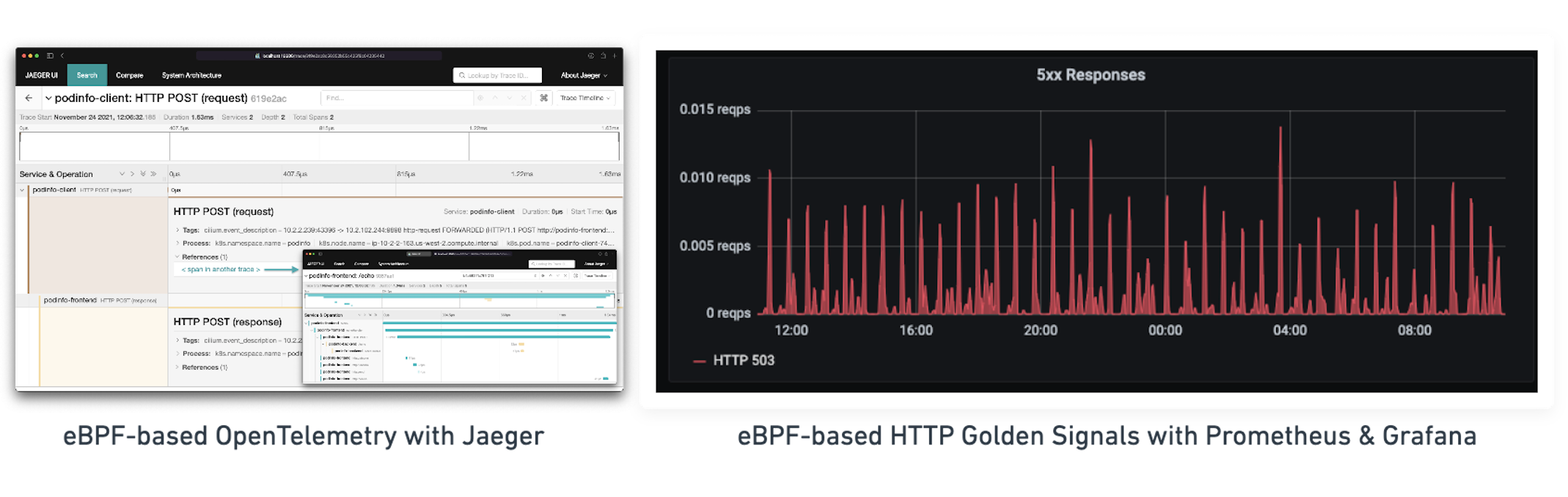
在下面的基准测试中,我们可以看到早期的测量结果,即通过eBPF或sidecar方法实现HTTP可见性对延迟的影响。 该测试是在两个不同节点上运行的两个pod之间,通过固定数量的连接每秒稳定地执行 10K 个HTTP请求,并测量请求的平均延迟。

我们故意不提这些测量中使用的具体代理,因为它并不重要。对于我们测试过的所有代理,结果几乎都是一样的。要明确的是,这不是关于Envoy、Linkerd、Nginx或其他代理是否更快的实验。所提到的代理有差异,但与首先注入代理的成本相比,它们是微不足道的。几乎没有开销是来自代理本身的逻辑。开销是通过注入代理、将网络流量重定向到它、终止连接和启动新连接而增加的。
这些早期的测量结果表明,基于 eBPF 的内核方法是非常有前途的,可以实现完全透明的服务网状结构的愿望,而且没有明显的开销。
eBPF Accelerated Per-Node Proxy
越来越多的用例可以用这种仅有eBPF的方法来覆盖,从而完全取消L4代理。对于一些用例,仍然需要一个代理。例如,当连接需要拼接时,当TLS终止被执行时,或对于某些形式的HTTP授权。
我们的eBPF服务网格工作将继续关注那些从性能角度可以获得最大收益的领域。如果你必须执行TLS终止,你可能不介意在流量流入集群时终止一次与代理的连接。然而,你会更关心在每个连接的路径中注入两个代理的影响,只是为了提取HTTP指标和跟踪数据。
当一个用例不能用纯eBPF的方法来实现时,服务网格可以 fallback 到 per-node 的代理模型,直接将代理与内核的套接字层结合起来。

eBPF不依赖网络层的重定向,而是直接在套接字级别注入代理,保持短路径。在 Cilium 的案例中,正在使用 Envoy,尽管从架构的角度来看,任何代理都可以被整合到这个模型。从概念上讲,这允许将Linux内核网络命名空间的概念直接扩展到Envoy监听器配置的概念,并将Envoy变成一个多用户代理。
Sidecar vs per-Node Proxy
即使需要代理,代理的成本也会根据部署的架构而有所不同。让我们来看看 per-node 的代理模式与 sidecar 模式的比较,看看它们是如何比较的。
Proxies per Connection
所需的网络连接数将会根据图片上的代理模式发生变化。最简单的场景是 sidecar-free 模型,这意味着网络连接的数量没有变化。一个连接就能够 serve 请求,eBPF 将会在已有的连接上提供追踪,负载均衡等服务网格的能力。

用 sidecar 模型实现同样的功能,需要在连接中注入两次代理,这就导致了需要维护三个连接。进一步导致开销的增加和套接字缓冲区所需的内存倍增,表现为更高的服务到服务的延迟。这就是我们之前在无 sidecar L7 可见性部分看到的 sidecar 开销。
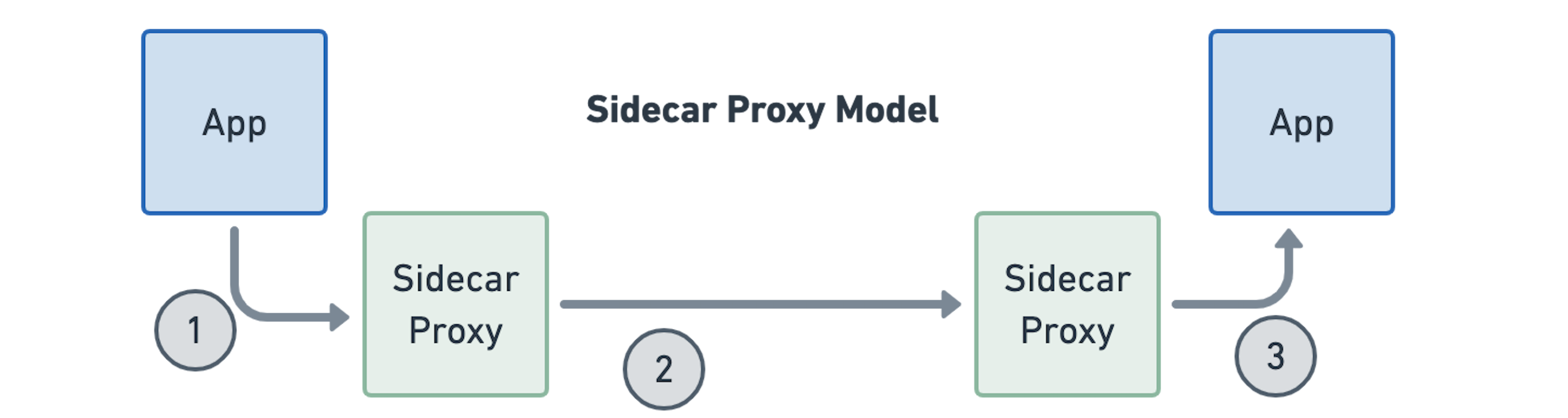
切换到 per-node 的代理模式使我们能够摆脱其中一个代理,因为我们不再依赖在每个工作负载中运行一个sidecar。比起不需要额外的连接,这还是不够理想,但比起总是需要两个额外的连接要好。

Total number of proxies required
在每个工作负载中运行一个 sidecar 会导致大量的代理。即使每个单独的代理实例在其内存占用方面是相当优化的,但实例的数量之多将导致总的影响很大。此外,每个代理维护的数据结构,如路由和端点表,随着集群的增长而增长,所以集群越大,每个代理的内存消耗就越高。今天,一些服务网格试图通过将部分路由表推送给单个代理来解决这个问题,限制他们可以路由到哪里。
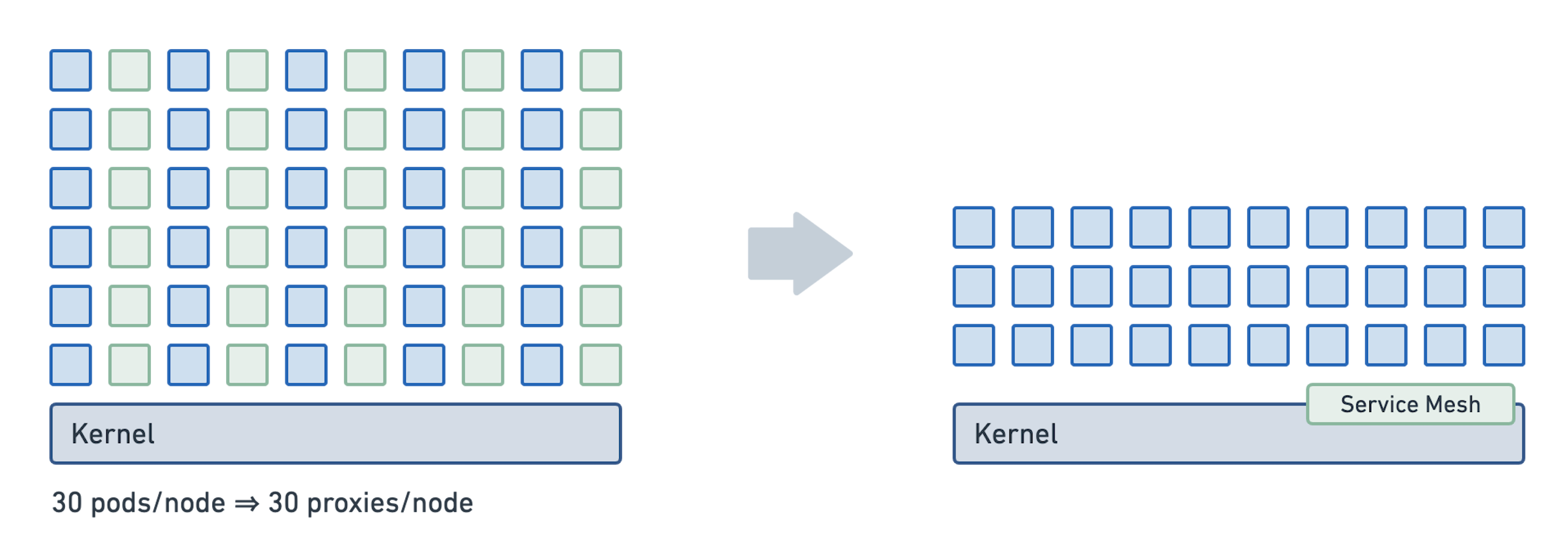
让我们假设在一个500个节点的集群中,每一个节点有30个pod,一个基于sidecar的架构将需要运行15K个proxy。在每个代理消耗70MB内存的情况下(已经假设了严重优化的路由表),这仍然导致集群中所有sidecar消耗1TB内存。在 per-node 模型中,假设每个代理的内存足迹相同,500个代理将消耗不超过34GB的内存。
Multi-Tenancy
当我们从 sidecar 模型转向 per-node 模型时,代理将为多个应用程序提供连接。代理必须有多租户意识。这与我们从使用单个虚拟机转向使用容器时发生的过渡完全相同。由于我们不再使用在每个虚拟机中运行的完全独立的操作系统副本,而开始与多个应用程序共享操作系统,Linux 必须有多租户意识。这就是命名空间和 cgroup 存在的原因。如果没有它们,一个容器可能会消耗一个系统的所有资源,容器可能会以不受控制的方式访问对方的文件系统。
如果在服务网格级别的网络资源上表现得完全一样,那不是很好吗?Envoy已经有了命名空间的初步概念,它们被称为监听器。监听器可以携带单独的配置并独立运行。这将开启全新的可能性:突然间,我们可以很容易地控制资源消耗,建立公平的排队规则,并将可用的资源平等地分配给所有的应用程序,或者按照指定的规则分配。这可以而且应该与我们今天在 Kubernetes 中定义应用程序的CPU和内存约束的方式完全一样。如果你想了解这个话题,我曾在EnvoyCon上讲过这个问题(Envoy Namespaces - Operating an Envoy-based Service Mesh at a Fraction of the Cost, Thomas Graf, EnvoyCon 2019)。
Want to get Involved? - Join the Cilium Service Mesh Beta

伴随着即将发布的Cilium 1.11,Cilium社区正在举办一个新的Cilium Service Mesh测试项目。它的特点是,新的构建将使以下功能可用。
- L7流量管理和负载平衡(HTTP、gRPC…)
- 跨集群、云和场所的拓扑感知路由
- TLS终结
- 通过Envoy配置的金丝雀展开、重试、速率限制、断路等。
- 通过OpenTelemetry和Jaeger集成进行追踪
- 内置Kubernetes入口支持
上述所有功能都可在 github.com/cilium/cilium 上的功能分支中找到。测试计划允许 Cilium 维护者直接与用户接触,了解他们的需求。要注册,你可以直接填写这个表格,或者你可以在 Cilium 社区的公告中阅读更多关于该计划的信息。
结论
eBPF是提供本地和高效的服务网格实现的答案。它将把我们从 sidecar 模型中解放出来,并允许将现有的代理技术整合到现有的内核命名概念中,使它们成为我们每天都在使用的美丽容器抽象的一部分。除此之外,eBPF将能够卸载越来越多的目前由代理执行的功能,以进一步减少开销和复杂性。通过能够整合几乎任何现有的代理,该架构也允许与大多数现有的服务服务网格(Istio、SMI、Linkerd…)整合。这将使eBPF的好处提供给广大的终端用户,同时将数据通路的效率和开销讨论与控制平面方面的问题相分离。
如果你对探索这一领域感兴趣,我们很愿意听到你的意见。请随时通过 Twitter 或eBPF & Cilium Slack联系我们。
Further Reading
- How eBPF Streamlines the Service Mesh, Liz Rice, The New Stack
- Cilium Service Mesh Beta Program, Cilium Community
- Learn more about Cilium