词法分析器生成工具 Lex 简介
结合例子简单介绍了Lex 程序和 Lex 工具的用法
Lex 说明
Lex 是一个词法分析器的生成工具,它支持使用正则表达式来描述各个词法单元的模式,由此给出一个词法分析器的规约,并生成相应的实现代码。 Lex 程序的输入方法称为 Lex 语言,而 Lex 程序本身被称为 Lex 编译器,Flex 是 Lex 编译器的一种替代实现( lex,flex 的关系和 cc,gcc 的关系很相似)。
在本文中,我们将会介绍 Lex 语言,并书写一个简单的 Lex 程序,进行词法分析,并输出分析结果。
Lex 程序的使用
Lex 程序的使用方法如下图所示:
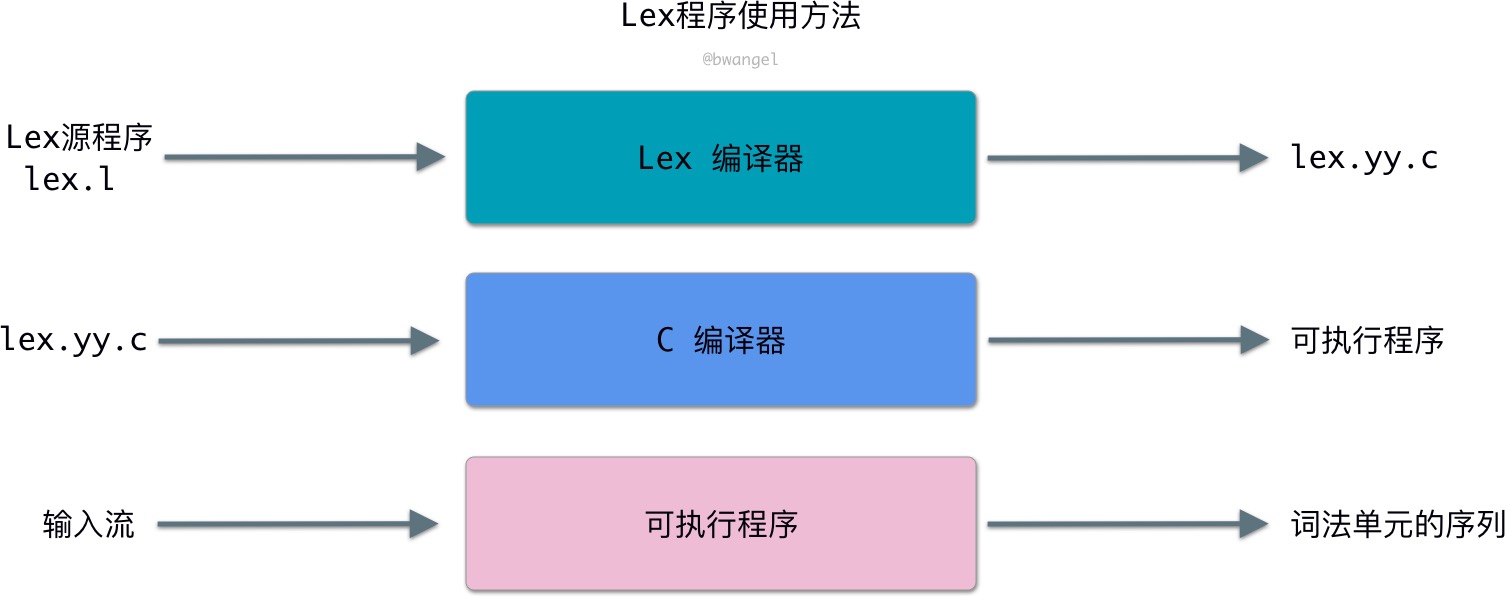
- 通过 lex 语言写一个 lex 源程序 lex.l
- 使用 Lex 编译器 flex 将 lex.l 编译成 C 代码, lex.yy.c
- 通过 C 编译器 cc 将 lex.yy.c 编译成可执行程序
- 运行可执行程序,输入源程序,输出词法单元序列
Lex 程序的结构
一个 Lex 程序通常具有如下形式:
声明部分
%%
转换规则
%%
辅助函数
声明部分
声明部分通常包括变量,明示常量和正则表达式的定义,明示常量是一个值为数字的标识符,用来表示词法单元的类型。
转换规则
转换规则具有如下的形式: 模式 { 动作 }。每个模式是一个正则表达式,可以使用声明部分给出的正则定义。动作部分是代码片段,通常用 C 语言编写。
辅助函数
这个部分中定义了各个动作所需要的函数,也可以包含 main 函数,这部分的代码将会放到输出的 C 代码中。
Lex 程序的工作方式
Lex 程序提供了一个函数int yylex()和两个变量yyleng,yytext供外部(通常是语法分析器)读取,调用。
当调用yylex的时候,程序会从yyin指针所指向的输入流中逐个读入字符,程序发现了最长的与某个模式
匹配的字符串后,会将该字符串存入到yytext变量中,并设置yyleng变量为该字符串的长度,该字符串也就是词法分析程序分析出来的一个词法单元。
然后,词法分析程序会执行模式
对应的动作
,并使用yylex函数返回
的返回值(通常是词法单元的类型)。
词法分析的例子
在下面的例子中,我们将会编写 Lex 程序,并生成生成一个词法分析器,分析 test1.p 程序,输出其词法单元和类型。
- test1.p
while a >= -1.2E-2
do b<=2
声明部分
首先定义的是声明部分,其中包含词法单元的类型,和一些正则表达式的定义
/* 明示常量的定义 */
#define IF 1
#define THEN 2
#define ELSE 3
#define ID 4
#define NUMBER 5
#define RELOP 6
#define DO 7
#define WHILE 8
%}
/* 正则表达式的定义 */
delim [ \t\n]
ws {delim}+
letter [A-Za-z]
digit [0-9]
id {letter}({letter}|{digit})*
number [+-]?{digit}+(\.{digit}+)?(E[+-]?{digit}+)?
需要注意的是,正则表达式中使用大括号包裹起来的内容表示嵌入另外一个正则表达式,例如ws的定义{delim}+就表示将之前定义的正则表达式delim嵌入进来。
转换部分
然后是转换部分,定义如下:
{ws} { }
if { return(IF); }
then { return(THEN); }
while { return(WHILE); }
do { return(DO); }
else { return(ELSE); }
{id} { return(ID); }
{number} { return(NUMBER); }
"<" { return(RELOP); }
"<=" { return(RELOP); }
"<>" { return(RELOP); }
">" { return(RELOP); }
">=" { return(RELOP); }
"=" { return(RELOP); }
这里的规则对应的动作都很简单,直接返回词法单元对应的类型。
辅助函数
最后是辅助函数部分,由于我们想输出一个可执行文件,所以这里会写一个 main 函数
void writeout(int c){
switch(c){
case RELOP: fprintf(yyout, "(RELOP, \"%s\")\n", yytext);break;
case WHILE: fprintf(yyout, "(WHILE, \"%s\")\n", yytext);break;
case DO: fprintf(yyout, "(DO, \"%s\")\n", yytext);break;
case NUMBER: fprintf(yyout, "(NUM, \"%s\")\n", yytext);break;
case ID: fprintf(yyout, "(ID, \"%s\")\n", yytext);break;
default:break;
}
return;
}
int main (int argc, char ** argv){
int c;
if (argc>=2){
if ((yyin = fopen(argv[1], "r")) == NULL){
printf("Can't open file %s\n", argv[1]);
return 1;
}
if (argc>=3){
yyout=fopen(argv[2], "w");
}
}
/* yyin和yyout是lex中定义的输入输出文件指针,它们指明了
* lex生成的词法分析器从哪里获得输入和输出到哪里。
* 默认:stdin,stdout。
*/
while ((c = yylex()) != 0) {
writeout(c);
}
if(argc>=2){
fclose(yyin);
if (argc>=3) fclose(yyout);
}
return 0;
}
我们在 main 函数中调用yylex函数获取到一个词法单元,然后调用writeout函数,将这个词法单元及其类型,输出到stdout中。
程序的编译执行
将上述程序写入到 lex.l 中,在 Mac 系统上,执行以下命令:
// flex 可以通过 brew install flex 安装
flex lex.l
cc lex.yy.c -o lex -ll
上述程序会生成可执行文件lex,然后我们执行 ./lex test1.p,就可以看到程序输出了词法单元及其类型。
>>> ./lex test1.p
(WHILE, "while")
(ID, "a")
(RELOP, ">=")
(NUM, "-1.2E-2")
(DO, "do")
(ID, "b")
(RELOP, "<=")
(NUM, "2")
上述例子的完整代码可以在 Github@896cc28 中找到。
Lex 中的冲突解决
在 Lex 编译器解析输入流时,针对同一个字符串可能会有多种解析模式,例如上述例子中,<=可以解析成(RELOP, "<"), (RELOP, "="),也可以解析成(RELOP, "<=")。当遇到这种冲突情况时,Lex 编译器遵循以下的规则:
- 总是选择最长的前缀进行匹配
- 如果最长的可能前缀与多个模式匹配,总是选择在 Lex 程序中先被列出的模式。
根据第二点可得,在上述例子中,{id}需要定义在if, then等关键字的后面,否则这些关键字就会被解析成 ID 了。