InnoDB 锁机制
本文试图讲清楚 InnoDB 中存在的各种锁,以及它们锁定的区别。
前言
锁是数据库系统区别于文件系统的一个关键特性,锁机制用于管理对共享资源的并发访问。不同数据库和不同搜索引擎都可能有不同的锁机制,MyISAM 引擎的锁是表锁设计,并发读没有问题,但是并发写入可能就存在一定的问题。
Microsoft SQL Server 在2005版本之前是页锁设计,相对于 MyISAM 并发性能有所提高,但是对于热点数据页的并发问题仍然无能为力。在2005版本中,SQL Server 开始支持乐观并发和悲观并发,在乐观并发下开始支持行级锁。但其实现方式与 InnoDB 完全不同,在 SQL Server 中锁是一种稀缺资源,锁越多开销越大,当锁过多的时候会出现锁升级,从行锁升级到表锁。
InnoDB 存储引擎锁的实现和 Oracle 数据库非常类似,提供一致性的非锁定读和行级锁支持。行级锁没有相关额外的开销,可以同时得到并发性和一致性。
lock 与 latch 的区别
在 MySQL 中 lock 与 latch 都可以被称为"锁",但是它们是不同的东西。
- latch 一般称为闩(shuan, 读一声)锁(轻量级的锁),它可以分为 mutex(互斥量) 和 rwlock(读写锁) ,它锁定的对象是内存中的共享资源,主要用来保证并发线程操作临界资源的正确性。
- lock 就是锁,它可以分为排他锁,共享锁,意向锁等,它锁定的对象是事务,主要用来锁定数据库中的对象,包括表,页,行等。
它们具体的区别可以用下表表示:
| 比较内容 | lock | latch |
|---|---|---|
| 锁定对象 | 事务 | 线程 |
| 保护内容 | 数据库内存 | 内存数据结构 |
| 持续时间 | 整个事务过程 | 临界资源 |
| 模式 | 行锁,表锁,意向锁等 | 读写锁,互斥量 |
| 死锁检测 | 通过 waits-for graph, time out等机制检测与处理 | 无死锁检测机制。仅通过应用程序加锁的顺序保证无死锁的情况发生 |
| 存在于 | Lock Manager的哈希表中 | 每个数据结构对象中 |
锁的类型
行级锁
InnoDB 存储引擎支持如下两种类型的行级锁:
- 共享锁(S Lock) 允许事务读取一行数据
- 排他锁(X Lock) 允许事务删除或者更新一行数据
如果一个事务T1已经获得了记录r上的共享锁,另一个事务T2也可以获得记录r上的共享锁,这种情况称为锁兼容。但如果T1获取的是记录r上的排他锁,则T2获取不了记录r上的共享锁,这种情况称为锁不兼容。 共享锁和排他锁的兼容情况如下所示:
| 共享锁 | 排他锁 | |
|---|---|---|
| 共享锁 | 兼容 | 不兼容 |
| 排他锁 | 不兼容 | 不兼容 |
注意: 共享锁和排他锁都是行锁,兼容指的是同一记录上的锁的兼容情况。
意向锁
InnoDB 存储引擎支持多粒度(multiple granularity locking)锁定,它允许表锁和行锁共存。为了支持在不同粒度上加锁,InnoDB 额外支持了一种表级锁类型,意向锁(Intention Locks)。
意向锁可以分为意向共享锁(Intention Shared Lock, IS)和意向排他锁(Intention eXclusive Lock, IX)。但它的锁定方式和共享锁和排他锁并不相同,意向锁上锁只是表示一种“意向”,并不会真的将对象锁住,让其他事物无法修改或访问。例如事物T1想要修改表test中的行r1,它会上两个锁:
- 在表
test上意向排他锁 - 在行
r1上排他锁
事物T1在test表上上了意向排他锁,并不代表其他事物无法访问test了,它上的锁只是表明一种意向,它将会在db中的test表中的某几行记录上上一个排他锁。
但是意向锁并不是完全和任何锁都兼容,在表级别上的意向锁也会和表级别的读锁(共享锁)和写锁(排他锁)冲突。比如下面的例子:
-- 事务A用读锁的方式锁定了表 table_lock
mysql root@(none):hp> start transaction;
Query OK, 0 rows affected
Time: 0.000s
mysql root@(none):hp> lock table table_lock read;
Query OK, 0 rows affected
Time: 0.013s
-- 事务B尝试向表 table_lock 中写入数据,它会在插入数据的语句中阻塞住
mysql root@(none):(none)> start transaction;
Query OK, 0 rows affected
Time: 0.001s
mysql root@(none):hp> insert table_lock select 1;
-- 此时我们查询 informaction_schema 数据中的 INNODB_TRX 表,会发现存在如下两个事务
-- 第一行代表了事务B,可以看到它锁定的表 trx_tables_locked 的数量为0
-- 第二行代表了事务A,可以看到它锁定的表 trx_tables_locked 的数量为1
mysql root@(none):information_schema> select * from `INNODB_TRX`\G
***************************[ 1. row ]***************************
trx_id | 421391658438288
trx_state | RUNNING
trx_started | 2018-03-08 19:57:28
trx_requested_lock_id | <null>
trx_wait_started | <null>
trx_weight | 0
trx_mysql_thread_id | 15
trx_query | insert into table_lock select 2
trx_operation_state | <null>
trx_tables_in_use | 0
trx_tables_locked | 0
trx_lock_structs | 0
trx_lock_memory_bytes | 1136
trx_rows_locked | 0
trx_rows_modified | 0
trx_concurrency_tickets | 0
trx_isolation_level | REPEATABLE READ
trx_unique_checks | 1
trx_foreign_key_checks | 1
trx_last_foreign_key_error | <null>
trx_adaptive_hash_latched | 0
trx_adaptive_hash_timeout | 0
trx_is_read_only | 0
trx_autocommit_non_locking | 0
***************************[ 2. row ]***************************
trx_id | 421391658436448
trx_state | RUNNING
trx_started | 2018-03-08 19:57:18
trx_requested_lock_id | <null>
trx_wait_started | <null>
trx_weight | 1
trx_mysql_thread_id | 6
trx_query | <null>
trx_operation_state | <null>
trx_tables_in_use | 1
trx_tables_locked | 1
trx_lock_structs | 1
trx_lock_memory_bytes | 1136
trx_rows_locked | 0
trx_rows_modified | 0
trx_concurrency_tickets | 0
trx_isolation_level | REPEATABLE READ
trx_unique_checks | 1
trx_foreign_key_checks | 1
trx_last_foreign_key_error | <null>
trx_adaptive_hash_latched | 0
trx_adaptive_hash_timeout | 0
trx_is_read_only | 0
trx_autocommit_non_locking | 0
2 rows in set
Time: 0.006s
-- 接着我们在事务A中执行解锁语句,并提交事务A
mysql root@(none):hp> unlock tables;
Query OK, 0 rows affected
Time: 0.011s
mysql root@(none):hp> commit;
Query OK, 0 rows affected
Time: 0.000s
-- 事务A在解锁了表后,事务B的插入语句立刻就完成了,此时我们再来看 INNODB_TRX 表,发现事务只有一个了:
-- 第一行代表了事务B,可以看到此时它锁定的表的数量(trx_tables_locked)变成了1
mysql root@(none):information_schema> select * from `INNODB_TRX`\G
***************************[ 1. row ]***************************
trx_id | 30221
trx_state | RUNNING
trx_started | 2018-03-08 19:57:28
trx_requested_lock_id | <null>
trx_wait_started | <null>
trx_weight | 2
trx_mysql_thread_id | 15
trx_query | <null>
trx_operation_state | <null>
trx_tables_in_use | 0
trx_tables_locked | 1
trx_lock_structs | 1
trx_lock_memory_bytes | 1136
trx_rows_locked | 0
trx_rows_modified | 1
trx_concurrency_tickets | 0
trx_isolation_level | REPEATABLE READ
trx_unique_checks | 1
trx_foreign_key_checks | 1
trx_last_foreign_key_error | <null>
trx_adaptive_hash_latched | 0
trx_adaptive_hash_timeout | 0
trx_is_read_only | 0
trx_autocommit_non_locking | 0
1 row in set
Time: 0.007s
所有表级别的锁的兼容性如下所示(其中S和X代表表级别的读锁和写锁):
| X | IX | S | IS | |
|---|---|---|---|---|
| X | Conflict | Conflict | Conflict | Conflict |
| IX | Conflict | Compatible | Conflict | Compatible |
| S | Conflict | Conflict | Compatible | Compatible |
| IS | Conflict | Compatible | Compatible | Compatible |
一致性非锁定读
一致性非锁定读是指 InnoDB 存储引擎通过行多版本控制(multi version)的方式来读取当前执行时间数据库中行的数据。具体来说就是如果一个事务读取的行正在被锁定,那么它就会去读取这行数据之前的快照数据,而不会等待这行数据上的锁释放。这个读取流程如图1所示:
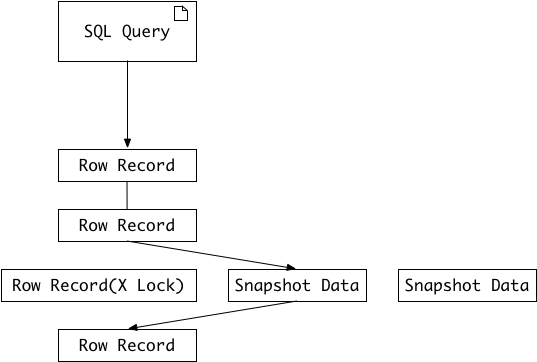
行的快照数据是通过undo段来实现的,而undo段用来回滚事务,所以快照数据本身没有额外的开销。此外,读取快照数据时不需要上锁的,因为没有事务会对快照数据进行更改。
MySQL 中并不是每种隔离级别都采用非一致性非锁定读的读取模式,而且就算是采用了一致性非锁定读,不同隔离级别的表现也不相同。在 READ COMMITTED 和 REPEATABLE READ 这两种隔离级别下,InnoDB存储引擎都使用一致性非锁定读。但是对于快照数据,READ COMMITTED 隔离模式中的事务读取的是当前行最新的快照数据,而 REPEATABLE READ 隔离模式中的事务读取的是事务开始时的行数据版本。
接下来我们通过一个例子来进行分析:
我们首先创建一个表lock_test,并向其中插入一条测试记录,如下所示:
CREATE TABLE `lock_test` (
`id` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into lock_test select 1
接着我们开启一个事务A,事务A更新表中的记录:
begin;
update lock_test set id = 4 where id = 1;
在事务A还未提交的时候,我们再来开启一个事务B,从lock_test表中查询这条记录:
begin;
select * from lock_test where id = 1;
+------+
| id |
|------|
| 1 |
+------+
1 row in set
Time: 0.006s
此时无论是在READ COMMITTED隔离级别下,还是在READ REPEATABLE隔离级别下,lock_test表中id为1的记录都能查找到,这是因为数据库事务的隔离性,未提交事务的更改不会影响到其他的事务。
然后我们把事务A提交,再在事务B中进行查找。
mysql root@(none):hp> select @@tx_isolation;
+------------------+
| @@tx_isolation |
|------------------|
| REPEATABLE-READ |
+------------------+
1 row in set
Time: 0.006s
mysql root@(none):hp> select * from lock_test where id = 1;
+------+
| id |
|------|
| 1 |
+------+
1 row in set
Time: 0.006s
--------------------------------
mysql root@(none):hp> select @@tx_isolation;
+------------------+
| @@tx_isolation |
|------------------|
| READ-COMMITTED |
+------------------+
1 row in set
Time: 0.006s
mysql root@(none):hp> select * from lock_test where id = 1;
+------+
| id |
|------|
+------+
0 rows in set
Time: 0.006s
此时我们可以看到,事务B在READ COMMITTED和READ REPEATABLE这两种不同的隔离级别下查找的结果不同。这个原因我们在上文中已经提过了,在READ COMMITTED隔离级别下读取的是行记录的最新快照版本,而在READ REPEATABLE隔离级别下读取的是事务开始时行数据版本。
其实,从数据库理论的角度来看,READ COMMITTED的隔离级别违反了事务的ACID特性中的隔离性。
一致性锁定读
在 InnoDB 存储引擎中,select语句默认采取的是一致性非锁定读的情况,但是有时候我们也有需求需要对某一行记录进行锁定再来读取,这就是一致性锁定读。
InnoDB 对于select语句支持以下两种锁定读:
select ... for updateselect ... lock in share mode
select ... for update会对读取的记录加一个X锁,其他事务不能够再来为这些记录加锁。select ... lock in share mode会对读取的记录加一个S锁,其它事务能够再为这些记录加一个S锁,但不能加X锁。
对于一致性非锁定读,即使行记录上加了X锁,它也是能够读取的,因为它读取的是行记录的快照数据,并没有读取行记录本身。
select ... for update和select ... lock in share mode这两个语句必须在一个事务中,当事务提交了,锁也就释放了。因此在使用这两条语句之前必须先执行begin, start transaction,或者执行set autocommit = 0。
锁的阻塞分析
Infomation Schema 中关于事务和锁的表
从 InnoDB 1.0 开始,在 INFORMATION_SCHEMA 数据库下添加了表 INNODB_TRX,INNODB_LOCKS 和 INNODB_WAITS。通过这三张表,用户可以更简单地监控当前事务并分析可能存在的锁问题。
INNODB_TRX 的表结构如下:
| 字段名 | 说明 |
|---|---|
trx_id |
InnoDB 存储引擎内部唯一的事务ID |
trx_state |
当前事务的状态 |
trx_started |
事务的开始时间 |
trx_requested_lock_id |
等待事务的锁ID。如果 trx_state 为 LOCK WAIT,那么该值代表当前事务等待之前事务占用的锁资源ID,否则这个字段为NULL。 |
trx_wait_started |
事务等待开始的时间 |
trx_weight |
事务的权重,代表事务修改和锁住的行数。当死锁发生时,InnoDB 会选择权重值最小的事务进行回滚。 |
trx_mysql_thread_id |
MySQL 中的线程ID,SHOW PROCESSLIST 显示的结果 |
trx_query |
事务运行的 SQL 语句 |
INNODB_LOCK_WAITS 表结构说明
| 字段名 | 说明 |
|---|---|
request_trx_id |
当前正在被阻塞的事务ID |
request_lock_id |
当前正在被阻塞的锁ID |
blocking_trx_id |
当前正在执行的事务ID |
blocking_lock_id |
当前正在阻塞的锁ID |
查询当前阻塞的事务
select
r.trx_id waiting_trx_id,
r.trx_mysql_thread_id waiting_thread_thread,
r.trx_query waiting_query,
b.trx_id blocking_trx_id,
b.trx_mysql_thread_id blocking_thread_thread,
b.trx_query blocking_query
from `INNODB_LOCK_WAITS` w
inner join `INNODB_TRX` b on b.trx_id = w.blocking_trx_id
inner join `INNODB_TRX` r on r.trx_id = w.requesting_trx_id\G
上述SQL语句会查找当前正在被阻塞的和阻塞的事务,并将其事务ID,MySQL执行线程ID,正在执行的查询都打印出来。
自增长与锁
MySQL 插入分类
| 插入类型 | 说明 |
|---|---|
| insert-like | insert-like 指所有的插入语句,如 insert,replace,insert … select, replace … select, load data等 |
| simple inserts | simple inserts 指在插入前就能确定行数的语句,包括 insert, replace等。但是其不包括 insert … on duplicate key update 这类 SQL 语句 |
| bulk inserts | bulk inserts 指插入前不能确定行数的 SQL 语句,例如 insert … select, replace … select, load data 等。 |
| mixed-mode inserts | mixed-mode inserts 语句指插入的数据中有一部分是自增长的,也有一部分的主键是已经确定的,例如:insert into t(c1, c2) values (1, ‘a’), (NULL, ‘b’), (4, ‘c’)。注意: insert … on duplicate key update 这类语句也属于 mixed-mode inserts。 |
InnoDB 锁类型
AUTO-INC Locking
在 InnoDB 存储引擎的内存结构中,每个含有自增长主键的表都有一个自增长计数器。当对含有自增长计数器的表进行插入时,这个计数器会被初始化,并通过以下语句来获得计数器的值:
select max(auto_inc_col) from t for update;
自增长计数器是一种特殊的表锁设计,因为在自增长计数器上的锁不会等到事务结束时才释放,而是在执行完插入语句后就被释放了。这种锁设计称为 AUTO-INC Locking。
轻量级互斥量锁
尽管 AUTO-INC Locking 在一定程度上提高了并发的插入效率,但还是存在一些性能上的问题,从 MySQL 5.1.22 版本开始,InnoDB 提供了一种轻量级互斥量的自增长实现方式,这种方式大大提高了自增长值插入的性能。并且从该版本开始,InnoDB 提供了一个innodb_autoinc_lock_mode的参数来确定自增长锁的锁模式。
InnoDB 自增长锁模式
innodb_autoinc_lock_mode共有三个值可以设置,即0,1,2。这三个值的具体功能如下:
| innodb_autoinc_lock_mode | 说明 |
|---|---|
| 0 | 这是在 MySQL 5.1.22 之前使用AUTO-INC Locking的方式来实现主键的自增长 |
| 1 | 这是该参数的默认值。对于simple inserts,该值会使用互斥量(mutex)去对内存中的计数器进行累加的操作。对于bulk inserts还是会使用传统表锁的AUTO-INC Locking的方式。在这种配置下,如果不考虑回滚操作,对于自增长列的键值还是连续的。这种方式下,statement-based 的 replication 还是能很好地工作的。 |
| 2 | 这种模式下,对于所有"INSERT-LIKE"自增长值的产生都是通过互斥量,而不是"AUTO-INC Locking"的方式。显然,这是性能最高的方式。但是这种模式在并发插入时,产生的自增长的值可能不是连续的。此外,在这种模式下,statement-based 的 replication 会出现问题。因此使用这种模式时需要使用 row-based 的 replication。 |
此外,MyISAM 和 InnoDB 不同,它是表锁设计,所以自增长不需要考虑并发插入的问题。
此外,在 InnoDB 存储引擎中,自增长的列必须是索引,而且必须是索引的第一个列,如果不是第一个列,MySQL 数据库会抛出异常。如下所示:
mysql root@localhost:hp> create table primary_table(
-> a int auto_increment,
-> b int,
-> key(b, a)
-> );
(1075, 'Incorrect table definition; there can be only one auto column and it must be defined as a key')
外键与锁
在InnoDB中,当我们在子表上添加记录时,会在相应的父表上添加一个共享锁。
例如存在一个父表parent和子表child,它们的结构如下:
mysql root@localhost:hp> show create table child;
+---------+-------------------------------------------------------------------------------+
| Table | Create Table |
|---------+-------------------------------------------------------------------------------|
| child | CREATE TABLE `child` ( |
| | `id` int(11) NOT NULL, |
| | `parent_id` int(11) NOT NULL, |
| | PRIMARY KEY (`id`), |
| | KEY `FK_PARENT` (`parent_id`), |
| | CONSTRAINT `FK_PARENT` FOREIGN KEY (`parent_id`) REFERENCES `parent` (`id`) |
| | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 |
+---------+-------------------------------------------------------------------------------+
mysql root@localhost:hp> show create table parent;
+---------+-----------------------------------------+
| Table | Create Table |
|---------+-----------------------------------------|
| parent | CREATE TABLE `parent` ( |
| | `id` int(11) NOT NULL, |
| | PRIMARY KEY (`id`) |
| | ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 |
+---------+-----------------------------------------+
我们先向父表中插入一条记录: insert into parent select 3。
接着,我们新开一个事务,称为事务A,在其中执行删除父表中id=3的记录,如下:
-- 事务A
mysql root@localhost:hp> begin;
Query OK, 0 rows affected
Time: 0.006s
mysql root@localhost:hp> delete from parent where id = 3;
Query OK, 1 row affected
Time: 0.002s
然后,我们再开一个事务B,在其中执行,向子表中插入(2, 3)的记录:
-- 事务B
mysql root@localhost:hp> begin;
Query OK, 0 rows affected
Time: 0.006s
mysql root@localhost:hp> insert into child select 2, 3;
此时事务B就会阻塞,因为在事务A已经在父表上添加了一个排他行锁。而事务B插入时需要在父表上id=3的行上添加一个共享锁,此时就会阻塞。
最后,我们把事务A提交,事务B立刻就会报错,提示相关的外键不存在:
-- 事务B
mysql root@localhost:hp> insert into child select 2, 3;
(1452, 'Cannot add or update a child row: a foreign key constraint fails (`hp`.`child`, CONSTRAINT `FK_PARENT` FOREIGN KEY (`parent_id`) REFERENCES `parent` (`id`))')
行锁
行锁的三种算法
InnoDB 存储引擎有三种行锁的算法,其分别是:
- Record Lock: 单个行记录上的锁
- Gap Lock: 间隙锁,锁定一个范围,但不包含记录本身
- Next-Key 锁: Gap Lock + Record Lock,锁定一个范围,并且会锁定记录本身
Record Lock 总是会去锁住索引记录,如果 InnoDB 表在创建的时候没有设置任何主键索引,那么 Record Lock 会锁住隐式的主键。
加锁场景分析
- 主键索引
如果我们加锁的行上存在主键索引,那么就会在这个主键索引上添加一个 Record Lock。
- 辅助索引
如果我们加锁的行上存在辅助索引,那么我们就会在这行的辅助索引上添加 Next-Key Lock,并在这行之后的辅助索引上添加一个 Gap Lock
辅助索引上的 Next-Key Lock 和 Gap Lock 都是针对 Repeatable Read 隔离模式存在的,这两种锁都是为了防止幻读现象的发生。
- 唯一的辅助索引
这里有一个特殊情况,如果辅助索引是唯一索引的话,MySQL 会将 Next-Key Lock 降级为 Record Lock,只会锁定当前记录的辅助索引。
如果唯一索引由多个列组成的,而我们只锁定其中一个列的话,那么此时并不会进行锁降级,还会添加 Next-Key Lock 和 Gap Lock。
- Insert 语句
在 InnoDB 存储引擎中,对于 Insert 的操作,其会检查插入记录的下一条记录是否被锁定,若已经被锁定,则不允许查询。
介绍了上面三种锁的加锁场景后,我们接着来看一个例子,存在一个表z,
-- 注意a列上有主键索引,b列上有辅助索引
Create Table | CREATE TABLE `z` (
`a` int(11) NOT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`a`),
KEY `b` (`b`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
表z中的数据如下所示:
+-----+-----+
| a | b |
|-----+-----|
| 1 | 1 |
| 3 | 1 |
| 5 | 3 |
| 7 | 6 |
| 10 | 8 |
+-----+-----+
通过上面表z中的数据,我们可以分析得出 Next-Key Lock 加锁的区间为:
(负无穷, 1]
(1, 3]
(3, 6]
(6, 8]
(8, 正无穷)
接着我们开启两个事务A和B,在事务A中执行如下的锁定语句:
-- 在事务A中执行
select * from z where b = 3 for update;
在执行完上述语句后,我们会在表z中添加上三个锁:
- 在主键列a的索引上添加一个 Record Lock,锁定住 a=5 的索引
- 在列b的辅助索引上添加一个 Next Key Lock,锁定住区间(1, 3]
- 在列b的辅助索引上添加一个 Gap Lock,锁定住区间(3, 6)
这里大家可能会疑惑,为什么在辅助索引上会加两个锁,这主要是为了防止事务A出现幻读,即事务A再次执行select * from z where b = 3时出现了多条语句。
因为列b并不是唯一的,所以其他事务也有可能插入b=3的记录到表z中。根据B+树索引的有序性,其他事务如果插入b=3的记录,那么就会在辅助索引上原有的b=3索引的前后区间中添加记录,如果我们把原有的b=3索引的前后区间锁住,那么其他事务就无法添加b=3的记录了,从而防止了幻读现象的出现。
分析完上面的锁情况之后,我们在事务B中执行插入语句,验证我们的想法:
-- 下面的语句会阻塞,因为和主键索引中的 Record Lock 锁冲突
mysql root@localhost:hp> select * from z where a = 5 lock in share mode;
^Ccancelled query
-- 下面的语句会阻塞,因为和辅助索引上的 (1, 3] Next-Lock 锁冲突
mysql root@localhost:hp> insert into z select 4, 2;
^Ccancelled query
-- 下面的语句会阻塞,因为和辅助索引上的 (3, 6) Gap Lock 锁冲突
mysql root@localhost:hp> insert into z select 6, 5;
^Ccancelled query
-- 以下的三条语句都不会阻塞
mysql root@localhost:hp> insert into z select 8, 6;
Query OK, 1 row affected
Time: 0.008s
mysql root@localhost:hp> insert into z select 2, 0;
Query OK, 1 row affected
Time: 0.007s
mysql root@localhost:hp> insert into z select 6, 7;
Query OK, 1 row affected
Time: 0.007s
死锁
死锁是指两个或两个以上的事务在执行过程中,因争夺锁资源而造成的一种相互等待的现象。若无外力作用,事务都将无法推进下去。
在InnoDB存储引擎中,可以通过超时机制来解决死锁问题,但超时机制是按照FIFO的顺序来进行回滚的,有可能我们回滚的事务做的更新比较多,对其回滚所用时间比回滚另一个事务要多的多,此时超时机制就不太合适了。
因此除了超时机制,还会采用wait-for graph的方式来进行死锁检测,这是一种更主动的死锁检测方式。
参考资料
- https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html#innodb-intention-locks
- https://dev.mysql.com/doc/refman/5.7/en/lock-tables.html
- https://www.percona.com/blog/2012/07/31/innodb-table-locks/
- http://hedengcheng.com/?p=771#_Toc374698309
- 《MySQL 技术内幕 – InnoDB 存储引擎》 第二版,第六章