InnoDB 行记录格式
简介: 本文主要讲述了 InnoDB 的行如何在数据文件中进行存储的,同时简单分析了 InnoDB 的逻辑存储结构
前言
InnoDB 是 MySQL 的一种面向行(row-oriented)存储引擎,即在其中数据是按照行的形式存储的,那么行又是如何组织的呢?在了解 InnoDB 的行格式之前,我们先简单了解一下 InnoDB 的逻辑存储结构。
InnoDB 逻辑存储结构
从 InnoDB 的逻辑存储结构上看,所有的数据都被存储在一个空间中,这个空间就叫做表空间,表空间又是由段(segment),区(extent)和页(Page)组成的,页在某些文档中也被称为块(block)。它们之间的关系可以用下图表示:
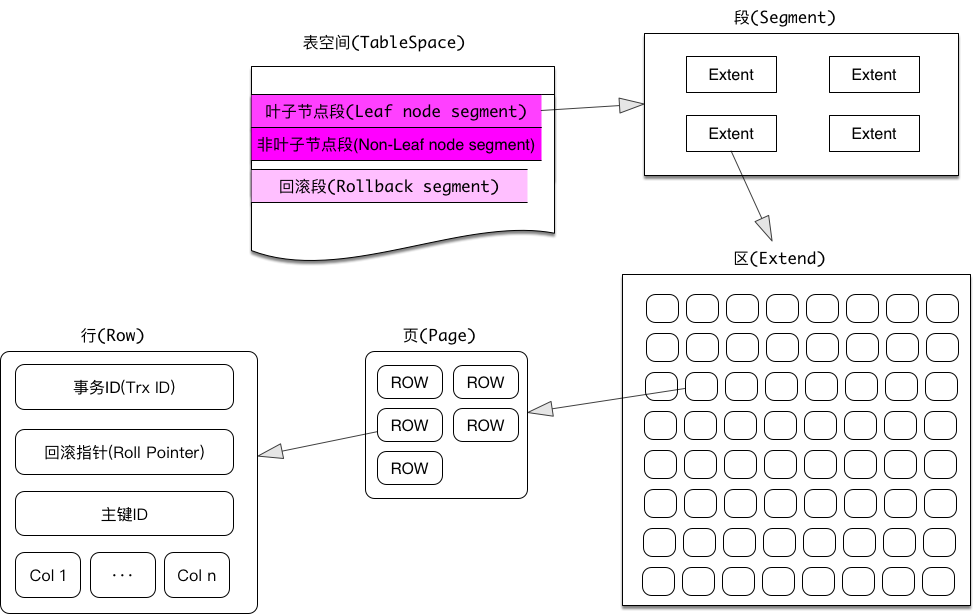
表空间
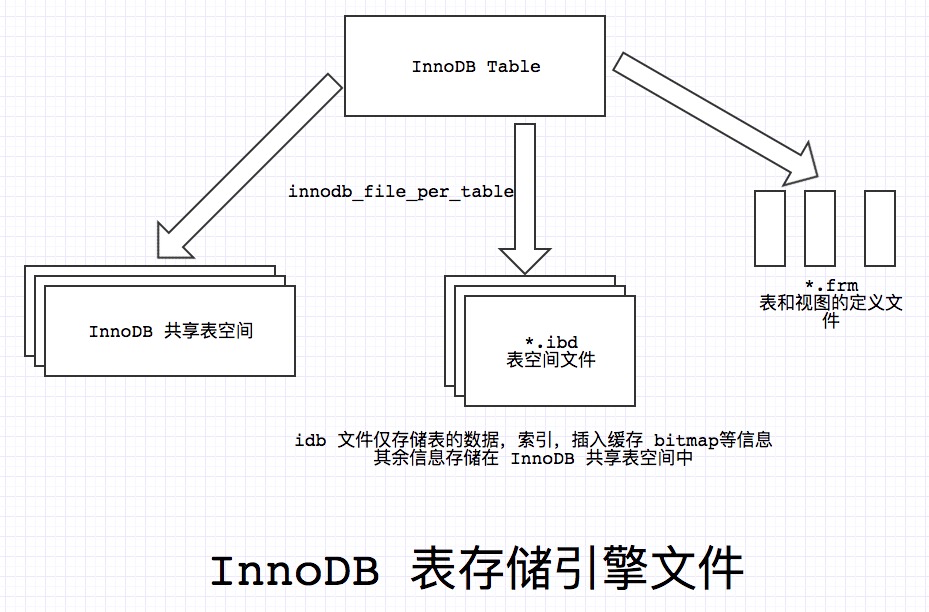
表空间是 InnoDB 逻辑存储的最高层,所有的数据都放在表空间中。当我们创建一个数据库的时候,它会产生后缀为idb和frm的文件,其中frm文件是MySQL的表和视图结构定义文件,idb文件是MySQL表的数据文件,我们说的表空间就存储在idb文件中。
当我们开启了 innodb_file_per_table 配置项后,InnoDB 会为每个表分配一个 独立表空间文件 ,但是这个文件只存储该表的数据,索引,插入缓存BITMAP等信息,其余信息还存放在 共享表空间文件 中。
关于idb和frm文件之间的关系可以用下图来表示:
段
InnoDB 的表空间是由各种段组成的,包括数据段,索引段和回滚段等。因为 InnoDB 存储引擎表是索引组织(index organized)的,因此数据段即为B+树的叶子节点,索引段即为B+树的非叶子节点。
区
区的大小为1M
MySQL创建表空间的时候,不先申请一整个区,而是先申请一些碎片页(33个)。如果表的空间持续增加,用完所有碎片页以后,才会去申请区,此时表空间文件(tablename.idb)的大小就会1M,1M地增加。
如果通过区申请空间,那么就会有很多空闲页(<Freshly Allocated Page>)。
页
InnoDB 的区是由页组成的,页主要有以下几种类型:
| InnoDB存储引擎中页的类型 | 十六进制 | 解释 |
|---|---|---|
FIL_PAGE_INDEX |
0x45BF | B+树叶节点 |
FIL_PAGE_UNDO_LOG |
0x0002 | Undo Log 页 |
FIL_PAGE_INODE |
0x0003 | 索引节点 |
FIL_PAGE_IBUF_FREE_LIST |
0x0004 | Insert Buffer 空闲列表 |
FIL_PAGE_TYPE_ALLOCATED |
0x0000 | 该页为最新分配 |
FIL_PAGE_IBUF_BITMAP |
0x0005 | Insert Buffer 位图 |
FIL_PAGE_TYPE_SYS |
0x0006 | 系统页 |
FIL_PAGE_TYPE_TRX_SYS |
0x0007 | 事务系统数据 |
FIL_PAGE_TYPE_FSP_HDR |
0x0008 | File Space Header |
FIL_PAGE_TYPE_XDES |
0x0009 | 扩展描述页 |
FIL_PAGE_TYPE_BLOB |
0x000A | BLOB页 |
InnoDB 行
Char 的行存储结构
从 MySQL 4.1版本开始,char(N)类型中的N表示的就是字符的长度,而不是字符串的长度。
举个例子,我们创建如下的表:
mysql> create table test_char(
-> c1 char(4)
-> )charset='gbk';
然后向其中插入数据,并查看其中的数据:
insert into test_char values('我们');
insert into test_char values('abc');
mysql> select length(c1), character_length(c1), c1 from test_char;
+------------+----------------------+--------+
| length(c1) | character_length(c1) | c1 |
+------------+----------------------+--------+
| 3 | 3 | abc |
| 6 | 3 | 我们 |
+------------+----------------------+--------+
我们可以看到,我们和abc的字符长度都是3,但是它们的字节长度是不同的。这也就意味着,在数据文件中存储的时候,char类型的字段也是被当做变长字段来存储的。
我们可以通过hexdump命令来查看test_char表对应的数据文件,具体命令如下:
hexdump -C -v /usr/local/var/mysql/hp/test_char.ibd |less
注意: 我的 MySQL 开启了innodb_file_per_table选项,所以每个表都会有自己单独的数据文件。上述命令中的/usr/local/var/mysql/hp/test_char.ibd文件是hp数据库中的test_char表的数据文件。
0000c090 01 10 61 62 20 20 06 00 00 00 18 00 20 00 00 00 |..ab ...... ...|
0000c0a0 00 06 08 00 00 00 1f 43 fb ba 00 00 01 2f 01 10 |.......C...../..|
0000c0b0 e6 88 91 e4 bb ac 04 00 00 00 20 ff b3 00 00 00 |.......... .....|
0000c0c0 00 06 09 00 00 00 1f 44 00 bd 00 00 01 35 01 10 |.......D.....5..|
0000c0d0 61 62 63 20 00 00 00 00 00 00 00 00 00 00 00 00 |abc ............|
在上面的二进制数据中,c096 - c0b5代表的是c1=我们这一行的数据,它的具体内容如下:
c1=我们行数据
| 二进制内容 | 具体含义 |
|---|---|
| 06 | 变长字段c1的长度 |
| 00 | NULL标志位 |
| 00 00 18 00 20 | Record Header |
| 00 00 00 00 06 08 | 隐式创建的行 ID |
| 00 00 00 1f 43 fb | 事务ID |
| ba 00 00 01 2f 01 10 | 回滚指针 |
| e6 88 91 e4 BB AC | 列数据字符串’我们' |
c1=abc行数据
| 二进制内容 | 具体含义 |
|---|---|
| 04 | 变长字段c1的长度 |
| 00 | NULL标志位 |
| 00 00 20 ff b3 | Record Header |
| 00 00 00 00 06 09 | 隐式创建的行ID |
| 00 00 00 1f 44 00 | 事务ID |
| bd 00 00 01 35 01 10 | 回滚指针 |
| 61 62 63 20 | 列数据字符串’abc’,另外加上补全4字符的空格 |
疑惑: 这里CHAR类型补全空格的规则是什么(例如中文什么时候会补全?),我还不太了解,如有了解的同学,希望可以指出
从上面的例子分析中,我们可以看到。MySQL 4.1 之后,CHAR(N)类型中的长度N表示的就是字符的长度,所以底层存储的字符数据实际上是变长的,MySQL也是将它按照变长数据的类型来处理的。