Redis 源码阅读之 dict
本文主要介绍了 Redis 的基础数据结构 dict 的实现,并描述了其渐进式 rehash 的操作
注意: 本文基于 Redis 3.0.0 的代码进行分析的
dict 介绍
dict 又称符号表(symbol table),关联数组(associative array)或映射(map),是一种用于保存键值对的抽象数据结构。
Redis 实现使用的C语言并没有内置 dict 这种数据类型,所以 Redis 实现了自己的 dict。dict 在 Redis 中有广泛的应用,Redis 数据库的底层就是使用字典来实现的,也就是说对数据库的增,删,改,查都是建立在字典之上的。同时,字典也是hash和sorted set等数据结构的底层实现之一。
dict 的实现
在 Redis 中,dict 的代码存放在src/dict.c和src/dict.h两个文件中。在src/dict.h中定义了 dict 所用到的结构体,一共有四个:
// 哈希表项
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 哈希表中是通过单链表解决键索引冲突的,next用来指向同一个键索引下的下一个元素
} dictEntry;
// 这里的思想类似于Go,使用函数来定义字典类型(接口)
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* 哈希表结构体,每个字典都有两个哈希表,其中多的一个用来做渐进式 rehash */
typedef struct dictht {
dictEntry **table; // 哈希表项组成的数组
unsigned long size; // 当前哈希表的大小
unsigned long sizemask; // 哈希表大小的掩码,总是等于size - 1
unsigned long used; // 哈希表中哈希表项的数目
} dictht;
/* 字典的定义 */
typedef struct dict {
dictType *type; // 字典的类型
void *privdata; // 字典私有数据
dictht ht[2]; // 字典中的哈希表
long rehashidx; // rehashidx == -1 表示当前字典没有做 rehash,否则表示当前字典正在进行 rehash 操作
int iterators; // 安全迭代器的数量
} dict;
/*
* 字典迭代器用来获取字典中所有的项,其中迭代器可以分为安全迭代器和非安全迭代器两种
* 安全迭代器表示在迭代过程中可以调用字典的 dictAdd(), dictFind() 等接口
* 非安全迭代器在迭代过程中只能调用 dictNext() 接口
* */
typedef struct dictIterator {
dict *d; // 迭代器所关联的字典
long index; // 当前迭代器在字典中迭代的索引
int table, safe; // 哈希表的索引,当前迭代器是否是安全迭代器
dictEntry *entry, *nextEntry; // 当前迭代器所指向的哈希表项和下一个哈希表项
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint; // 字典的指纹,非安全迭代器中用于鉴别字典是否被修改过
} dictIterator;
他们之间的关系如图1所示:

图1
当我们向字典中存储键值对(k, v)时,字典通过一定的算法计算出k的索引值,它的计算方法如下:
# 先根据哈希算法计算出键k的哈希值,哈希值为unsigned int 类型
hash = d->type->hashFunction(k)
# 然后再将哈希值和哈希表的sizemask按位与,获得键k在哈希表中的索引
idx = hash & d->ht[table].sizemask
最后按照计算出来的索引值将键值对存储到字典中的哈希表中。
dict 的哈希算法
dict 按照使用方式的不同,所采取的哈希算法也不同。Redis目前共使用两种不同的哈希算法:
- MurmurHash2 32 bit 算法:这种算法的分布率和速度都非常好, 具体信息请参考 MurmurHash 的主页: http://code.google.com/p/smhasher/ 。
- 基于 djb 算法实现的一个大小写无关散列算法:具体信息请参考 http://www.cse.yorku.ca/~oz/hash.html 。
- dict 在命令表以及 Lua 脚本缓存中时,使用了算法2
- dict 在数据库,集群,哈希键和阻塞操作等功能中都使用到了算法1
dict 解决键冲突的方案
根据前面的内容所知,向dict中添加键值对时,dict根据键计算出来的索引值将键值对存储到哈希表中。由于哈希表的大小是有限的,所以可能会出现两个键的索引值相同的情况,这种情况也称作键冲突。
当出现键冲突的时候,dict会将两个键值对存放在同一个哈希表的同一个索引下,它们通过单链表的形式组合起来,如图2所示:
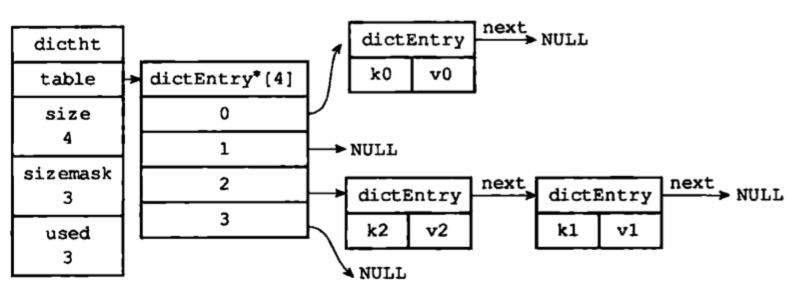
图2
其中k1和k2计算出来的索引值是相同的,他们被存放到哈希表的同一个索引下,然后通过单链表的形式组合起来。
在 src/dict.c的dictEntry *dictAddRaw(dict *d, void *key)函数中,我们可以看到向单链表中添加元素的过程
/* 哈希表通过单链表来解决键冲突,下面的代码向单链表中添加了哈希表节点 */
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
申请一个哈希表项之后,将它的地址存放在哈希表中,同时也使哈希表中原来存在的节点变成它的next节点,即新增元素在单链表的头部。
渐进式 rehash
每个dict都有一个负载因子,计算方式如下:
load_factor = ht[0].used / ht[0].size
当 dict 的负载因子过大或过小的时候,Redis 需要为这个 dict 扩展或者收缩哈希表的大小,这个过程叫做 rehash。上文中我们提到每个 dict 都有两个哈希表, ht0和ht1,在这里它们就发挥作用了。rehash 的具体操作如下:
-
设置
ht1的size,扩展过程中size为大于ht0.size的最小2次幂,收缩过程中size为大于ht0.used的最小2次幂 -
将 dict.rehashidx 设置为0
-
在增删改查的过程中,检查 dict.rehashidx 是否不等于 -1,如果是,那么就执行
_dictRehashStep操作,_dictRehashStep的操作如下:- 如果当前字典上的没有安全迭代器,执行
dictRehash操作 dictRehash操作就是从ht0中取出值,重新计算哈希值,然后放到ht1中,并将ht0.used减少。将dict.rehashidx的索引加1。由于在这个过程中重新计算了 key 的哈希值,所以这个过程称为 rehash- 如果
ht0中的所有元素都复制到了ht1中后,Redis 会交换ht1和ht0的地址,然后将ht1置为空表(即存在dictht这个结构体变量,但是里面的dictEntry指针为空,没有任何哈希表项),同时将dict.rehashidx置为 -1。 - 同时
dictRehash还有一个限制,每次 rehash 的时候存在一个empty_visits限制(empty_visits = 10 * n,n是本次dictRehash操作要 rehash 哈希表项的数量)。如果访问到的空的哈希表项的次数超过了empty_visits,本次 rehash 操作就结束了。
- 如果当前字典上的没有安全迭代器,执行
-
由于 rehash 操作不是一次性做完的,而是在字典的操作中一点一点做的,所以这个过程称作__渐进式rehash__
-
因为在字典的增删改查操作中执行了 rehash 操作,所以这些操作的行为也会受到影响
- 在
dictAdd操作中,如果当前字典正在进行 rehash,那么新加的值都会加入到ht1中,这样保证ht0只会减少,不会增加,最终ht0会变成空表 - 在
dictFind操作中,会在ht0和ht1两个哈希表中查询对应的键 - 在
dictDelete操作中也回在ht0和ht1中查找对应的键 dictReplace操作调用的是dictFind方法查找对应的键
- 在
-
在执行 BGSAVE 和 BGREWRITEAOF 命令时,Redis 会提高字典的负载因子。因为在调用这两个命令时,Redis 会为当前进程产生子进程,而很多操作系统采用了写时复制的策略,如果不执行 rehash 操作,会避免不必要的内存写入操作,从而节省一些内存。
字典迭代器和 rehash 的关系
在渐进式 rehash 一小节中我们提到,当字典的安全迭代器的数量为0的时候,才会执行 rehash 操作,这是为什么呢?
首先我们可以分析一下字典迭代器的迭代操作,它可以用如下的伪代码来表示:
def iter_dict(dict):
# 迭代0号哈希表
iter_table(ht[0]->table)
# 如果正在进行 rehash 的话,也迭代1号哈希表
if dict.is_rehashing():
iter_table(ht[1]->table)
def iter_table(table):
for index in table:
# 跳过空的哈希表项
if table[index].empty():
continue
# 处理当前哈希表项的单链表上所有的节点
for node in table[node]:
do_some_thing_with(node)
假设我们在一个正在进行 rehash 操作的字典上创立了一个安全迭代器,首先执行了dictNext(),获取了ht0中的一个哈希表项he1。接着执行dictAdd(),添加了一个哈希表项。如果dictAdd()函数能够执行 rehash 的话,he1哈希表项可能被从ht0复制到了ht1,从而导致安全迭代器获取了哈希表项he1两次
所以当字典中存在安全迭代器的时候,是不能进行 rehash 操作的。
而对于非安全迭代器,Redis 规定在非安全迭代器的生命周期内只能执行dictNext()操作,不能执行其他操作,从而避免了 rehash 操作。
同时 Redis 在创建非安全迭代器的时候会获取 dict 的指纹,在释放非安全迭代器的时候重新获取指纹,检查两次指纹是否相同。如果不同,证明 dict 被修改过,Redis 就会抛出异常。