Rabbitmq Tutorial 学习笔记
- RabbitMQ Tutorial 学习笔记
- 本文相关代码放在 Github@bwangelme/RabbitMQDemo 中
RabbitMQ 基础概念介绍
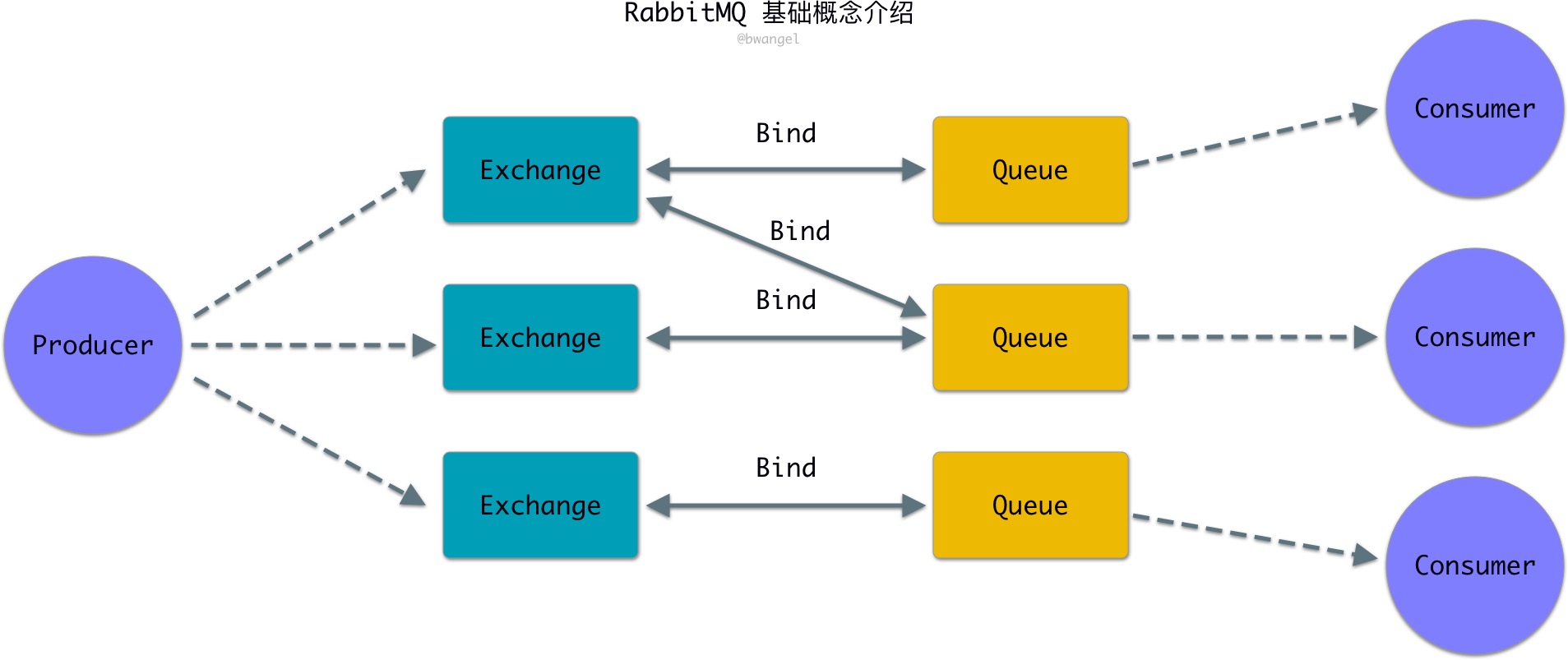
上图展示的 RabbitMQ 的一些基础概念和它们之间的关系。这里为了方便展示,只显示了一个生产者,且每个消费者只绑定了一个队列。
生产者(Producer)将消息发布(Pubscribe)到交换机(Exchange)上,交换机将消息转发给一个或多个(根据交换机的类型确定)队列(Queue)。队列将收到的消息发送给订阅(Subscribe)该队列的消费者(Consumer)。
Publish
生产者将消息发送到交换机的过程称为Publish,下面是Publish的示例代码:
err = ch.Publish(
"", // exchange
"abcd", // Route key
false, // mandatory 强制的
false, // immediate 即时的
amqp.Publishing{
DeliveryMode: amqp.Persistent,
ContentType: "text/plain",
Body: []byte(body),
},
)
Publish的前两个参数分别是交换机名称和Route Key。
我们在这里将消息发送给了无名交换机(即交换机的名称为空字符串""),这是 RabbitMQ 默认就会创建的交换机,它是direct类型(关于交换机的类型会在下文中讲述)。
队列与 Binding
生产者直接将消息发送给交换机,但是消费者不能直接从交换机读取消息。
它需要创建一个队列,将队列和交换机绑定(Bind)起来,然后才能从队列中收到交换机转发过来的消息。
消费者从队列读取消息的过程称为Consume,队列和交换机的绑定关系叫做Binding。
创建临时队列
当我们需要创建一个只用一次的队列时,可以通过指定exclusive=true参数来实现:
q, err := ch.QueueDeclare(
"", // name
false, // durable
false, // delete when unused
true, // exclusive
false, // no-wait
nil, // arguments
)
上述代码创建了一个临时队列,在 Channel(客户端和 RabbitMQ 交互的中介)关闭之后,该队列就会被自动删除,注意指定了三个参数,name="", durable=false(不进行持久化存储), exclusive=true(只使用一次)。
上述代码会返回一个临时队列,队列的名字类似于这样: amq.gen-JzTY20BRgKO-HjmUJj0wLg。想要了解 Exclusive 队列的更多信息,请参考文档 Guide on Queues
通过rabbitmqctl list_queues 可以查看我们创建的所有队列。
ø> rabbitmqctl list_queues
Timeout: 60.0 seconds ...
Listing queues for vhost / ...
name messages
hipri 0
task_queue 0
second 0
celery 0
创建和查看 Binding
将队列绑定到交换机的代码如下,前三个参数分别是队列名称,Bind Key,和交换机名称。
err = ch.QueueBind(
q.Name, // queue name
"", // bind key
"logs", // exchange name
false,
nil,
)
通过 rabbitmqctl list_bindgs 命令我们可以查看 RabbitMQ 中所有的 Binding。
Consume
消费者从队列中读取消息的过程称为Consume
下面是Consume的示例代码,返回值msgs是Go语言中的 channel 类型,消费者可以从中读取队列返回的的消息。
msgs, err := ch.Consume(
q.Name, // name
"", // consumer
true, // auto ack
false, // exclusive
false, // no-local
false, // no-wait
nil, // args
)
交换机的类型与特性
交换机一端接收消息,另外一端发送消息到队列中。
交换机处理消息的方式是由它的类型决定的,交换机共有这么几种类型: direct, topic, headers, fanout。
查看交换机
通过命令 rabbitmqctl list_exchanges 就可以列出所有的交换机:
>>> rabbitmqctl list_exchanges
Listing exchanges for vhost / ...
name type
amq.fanout fanout
amq.headers headers
amq.match headers
amq.direct direct
amq.topic topic
direct
amq.rabbitmq.log topic
amq.rabbitmq.trace topic
我们可以看到 RabbitMQ 中已经预置了 amq.* 交换机和一个无名交换机("")。无名交换机是默认交换机,所有未指定交换机名称的消息都会发到这里来。
Direct 交换机
我们将Publish时指定的key称为Route Key, 将消费者 Bind 到交换机时指定的key成为 Bind key。
Direct 交换机的转发逻辑很简单,就是寻找声明的 Bind key == Route key 队列,然后将消息转发到该队列上。
它支持一个队列使用多个Bind Key,也支持多个队列使用同一个 Bind key。
Direct 交换机示例
下图是一个 Direct 交换机的完整例子,我们使用日志等级名称作为Route Key。
2号消费者绑定了debug key,3号消费者绑定了info key。可以看到,1号生成者分别发送了两条消息,这些消息根据Route Key的不同,发送到了不同的消费者上。
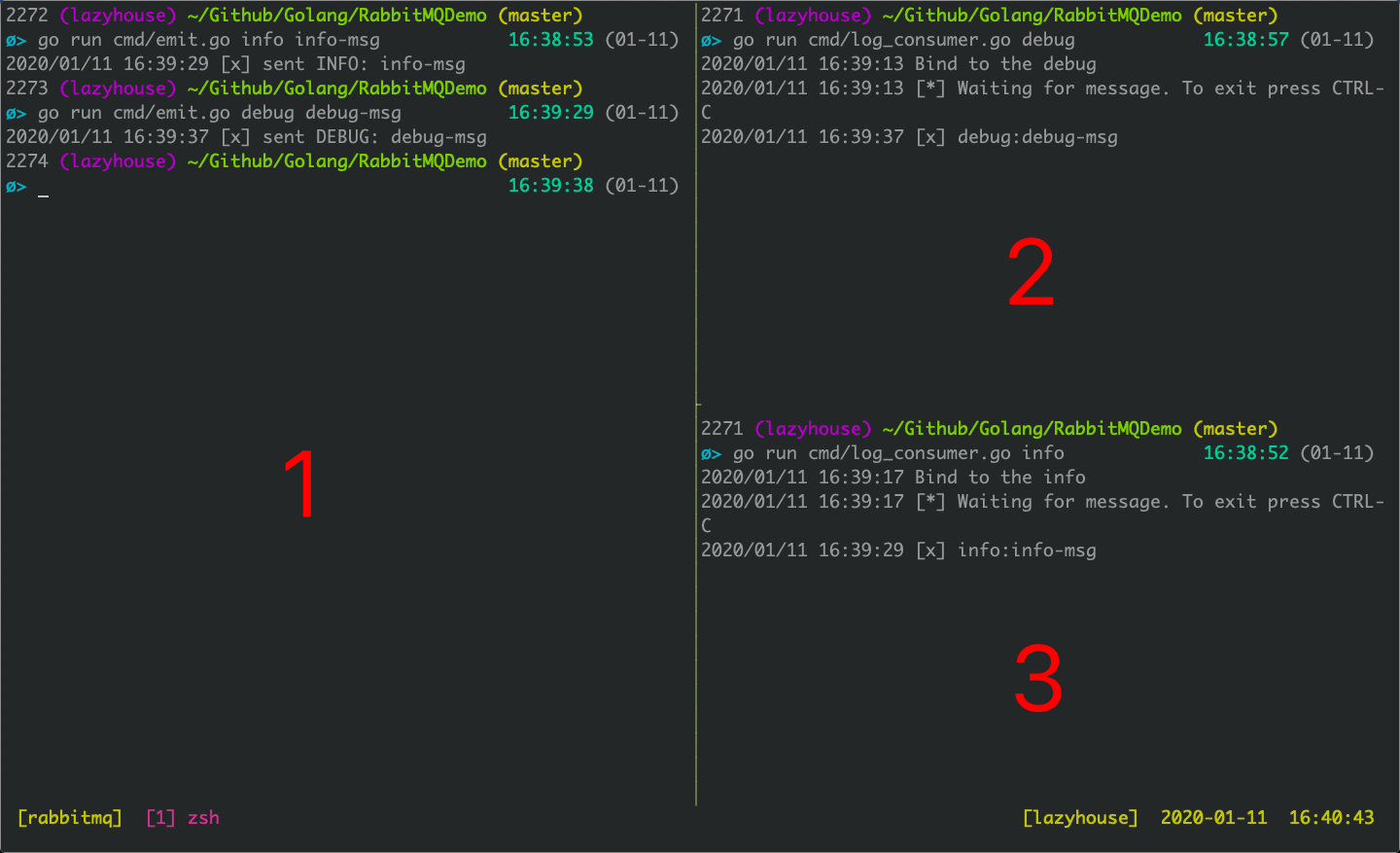
该示例的代码详见 Github@3593d57 。
Fanout 交换机
Fanout 类型交换机的转发策略非常简单,它就是将收到的消息发送给所有绑定的队列,这点从它的名字(Fanout 扇出)就可以看出。
Fanout 交换机示例
下图是 Fanout 交换机的例子,2号消费者和3号消费者将不同的队列绑定到了同一个 Fanout 交换机上,然后1号生产者发出了两条消息,这两个消费者都收到了。
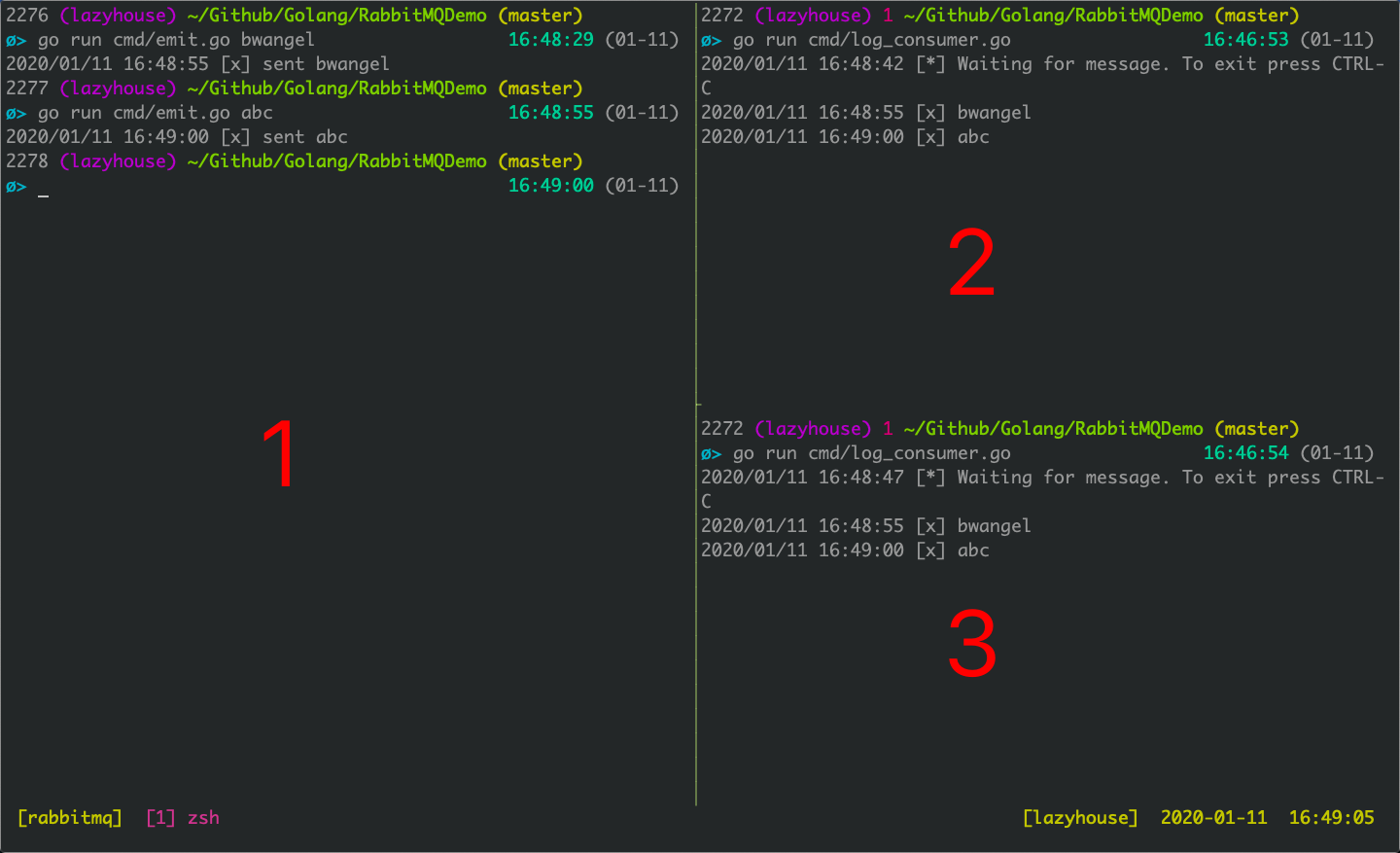
该示例的代码详见 Github@cf8f902
Topic 交换机
Topic 交换机 也是按照Bind Key对Route Key进行匹配,不过它可以指定Bind Key的模式,匹配一批Route Key。
Route Key按照.分割,.之间的内容称为一个单词。Bind Key支持两个通配符#和*,#代表一个或多个单词,*代表一个单词。
例如Route Key a.# 会匹配 a.b.c.d, a.b.c 等,a.*只会匹配a.b, a.c,不会匹配a.b.c
如果Bind Key中没有#和*通配符,那么这个 Topic 交换机其实就是一个 Direct 类型的交换机,
同理,如果Bind Key是#,那么这个 Topic 交换机就是一个 Fanout 类型的交换机。
Topic 交换机示例
下图是一个 Topic 交换机的例子,我们做了一个收集日志的简易客户端,Route Key遵循模块.级别的模式。生产者可以订阅不同模式的日志,然后将日志写到不同的文件中。
其中2号消费者订阅的是所有模块info级别和所有net模块的日志,3号消费者订阅的是kernel模块debug级别的日志。
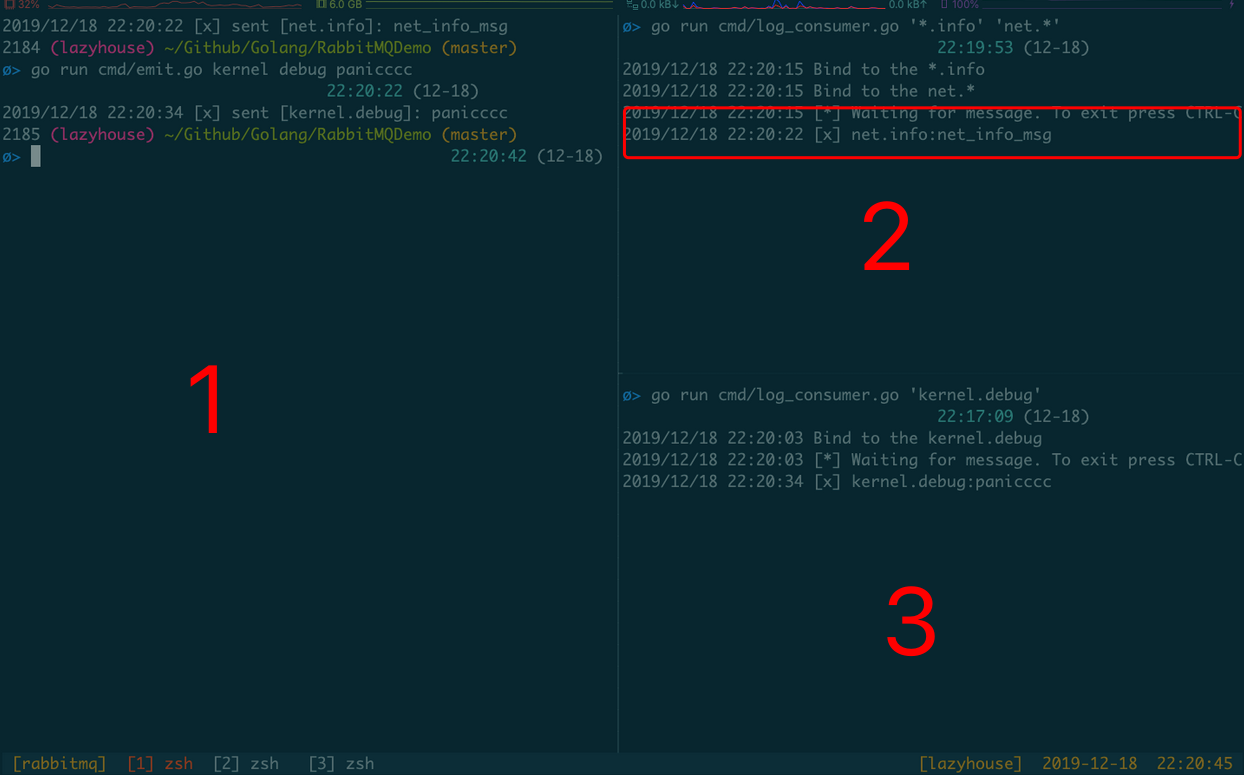
该示例的代码详见 Github@b56c3b1
注意红框内的消息,1号生产者发送了Route Key = net.info的一条消息,
但由于2号消费者中__只有一个队列__绑定了*.info和net.*这两个模式,所以2号消费者只收到了一条消息。
消息的分发与确认
轮询分发
在 RabbitMQ 中,消息默认是通过轮询分发的方式进行发送的。具体来说,就是顺序地给绑定同一个队列的每个消费者发送消息,平均下来,每个消费者获得的消息数量是相同的。
可以参考下面这个例子:
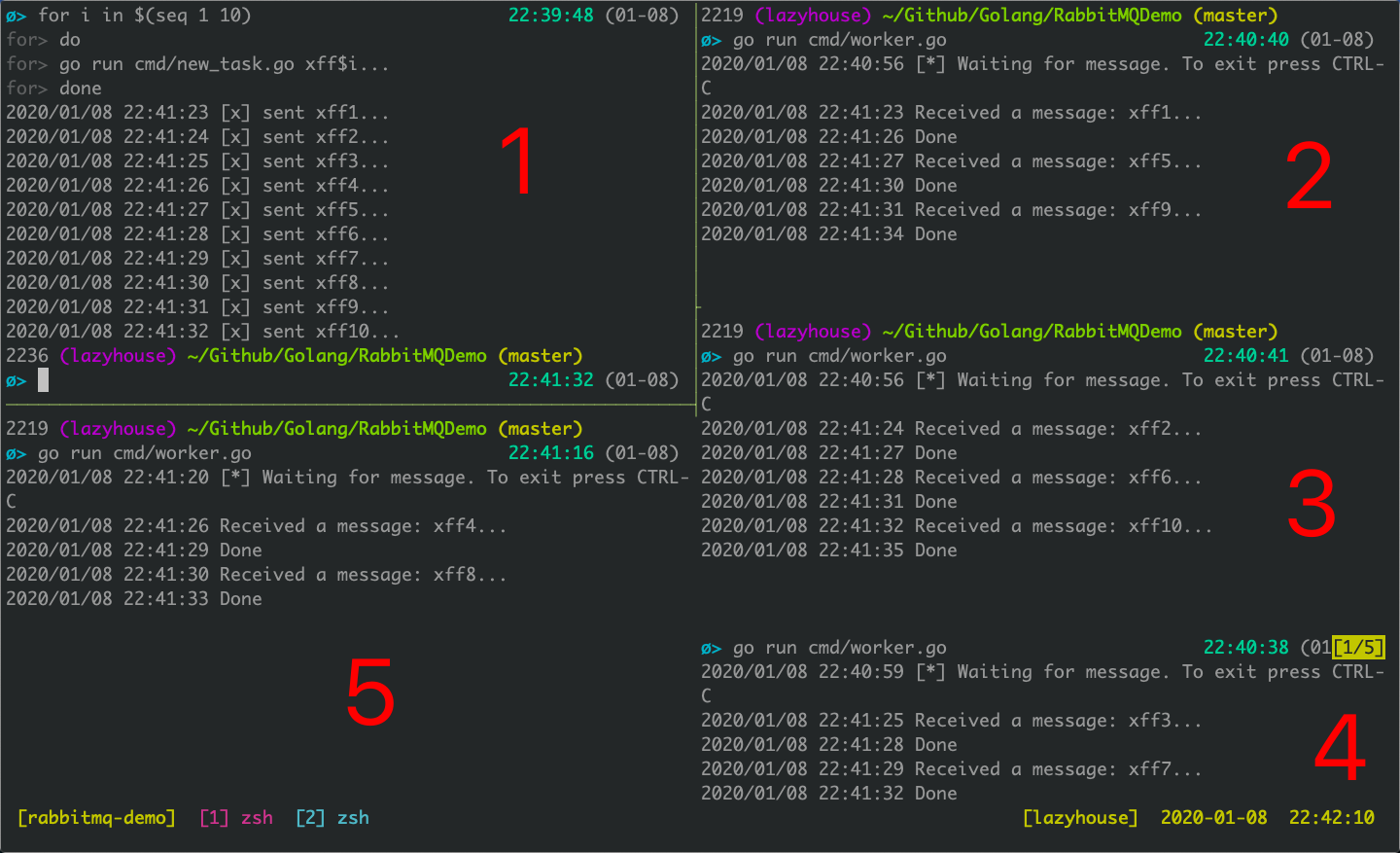
该示例的代码详见 Github@41c82064 。
1号窗口是生产者,2,3,4,5号窗口都是消费者。
生产者一共发送了10条消息,他们被顺序地发送给四个消费者。
公平分发
轮询分发的策略有时候并不适合实际的业务,可能会导致某些消费者特别忙,但是另一些消费者很闲的情况。
例如下面的这个例子,消息中.的数量表示Sleep的秒数,.越多,表示工作越繁重。
1号生产者发送的奇数消息都很繁重,偶数消息都很轻松,导致2号消费者很忙,3号消费者很轻松()。
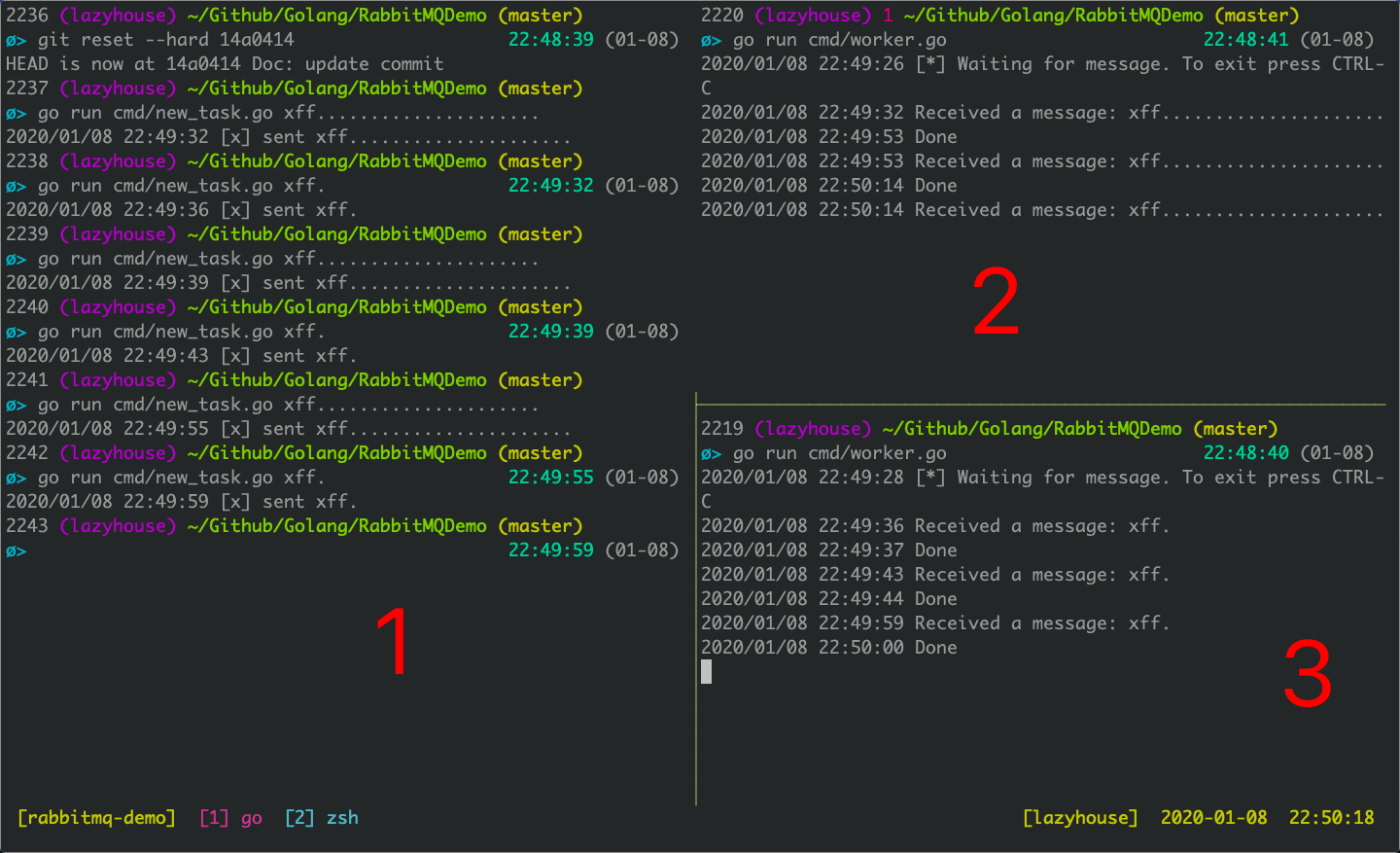
该示例的代码详见 Github@14a0414
为了避免这种极端情况的发生,我们可以设置预取值(prefetch count)为1。这样的话,相当于告诉 RabbitMQ,在 Worker 消费完一个消息之前,不要再给他分发新的消息了,这样的话随后的消息就会被分发给其他的空闲的 Worker 了。
在具体代码如下:
// 在 Worker 的代码中设置
err = ch.Qos(
1, // prefetch count
0, // prefetch size
false, // global
)
运行效果如下:

该示例的代码详见Github@ad5507e
可以看到2号窗口和3号窗口中的消费者都分配到了耗时较长的任务。
注意: 这样操作容易让 RabbitMQ 的队列被塞满,需要有合适的监控机制来监控消息的数量。
消息确认
当消费者收到消息后,可能会遇到某种异常崩溃了,此时这条消息就会丢失了。
为了避免这种情况,我们可以使用 RabbitMQ 提供的消息确认机制。
消费者在消费完消息后,再向 RabbitMQ 发送 ack。收到 ack 之后,RabbitMQ 才会把这条消息标记为可删除的,并择机删除。 如果 RabbitMQ 没有收到 ack,消费者就死掉了(channel 关闭,连接关闭,或者 TCP 连接关闭)。 那么 RabbitMQ 就会认为这条消息没有被消费完,它就会重新入队,然后被快速发送给其他消费者。
使用了消息确认机制后,我们就可以确保即使存在消费者偶尔崩溃的情况,我们的消息也不会丢失。
在消息确认机制中,没有任何的超时限制,所以即使客户端花费很长的时间去处理消息,也不用担心消息会被误重发。
具体代码如下,我们在消费者订阅的时候将auto_ack选项关掉,然后再在消费完消息后手动发送 Ack
// 消费者从队列订阅消息
msgs, err := ch.Consume(
q.Name, // name
"", // consumer
false, // 关闭掉 autoack
false, // exclusive
false, // no-local
false, // no-wait
nil, // args
)
go func() {
for d := range msgs {
log.Printf("Received a message: %s", d.Body)
dot_count := bytes.Count(d.Body, []byte("."))
t := time.Duration(dot_count)
time.Sleep(t * time.Second)
log.Printf("Done")
d.Ack(false) // 手动发送 ack
}
}()
示例如下,3号消费者在 23:08:54 收到消息后,还没有确认(确认后会打印 Done ),就被我们 kill 掉了。2号消费者在23:08:55重新收到了这条消息。

该示例代码详见Github@9cd87dd
持久化
通过消息确认,我们可以在消费者崩溃的情况下,让我们的消息不丢失。但如果 RabbitMQ 崩溃,或者 RabbitMQ 所在的节点宕机的话,消息仍然可能会丢失。
在这种情况下,我们可以使用消息和队列持久化,这样的话即使 RabbitMQ 退出,消息和队列也回被持久化到磁盘中,不会丢失。
声明队列持久化
声明队列持久化的代码如下:
q, err := ch.QueueDeclare(
"task_queue", // Queue name
true, // durable 持久性
false, // delete when unused
false, // exclusive 独占
false, // no-wait
nil, // arguments
)
注意: 在声明队列时,如果我们声明一个已经存在的队列,但是初始化参数不同的时候,QueueDeclare会失败并返回一个 err。
声明消息持久化
在发送消息的时候,我们可以设置一个 amqp.Persistent 选项,来表明这个消息应该被持久化。
err = ch.Publish(
"", //exchange
q.Name, // route key
false, // mandatory 强制的
false, // immediate 即时的
amqp.Publishing{
DeliveryMode: amqp.Persistent, // 声明消息持久化
ContentType: "text/plain",
Body: []byte(body),
},
)
关于消息持久化注意事项
上述声明消息持久化的代码,并不能100%保证消息不会丢失,有以下两方面的原因:
- 在 RabbitMQ 收到消息和 RabbitMQ 将消息写入磁盘这两个事件中仍然有一个短暂的时间窗口。如果在这个时间窗口内发生宕机的话,消息仍然会丢失。
- RabbitMQ 并不会每次收到消息后,都调用
fsync(2),消息可能被存储在缓存中,过一段时间后才被写入到磁盘中。
因此,这个持久化策略并不是强健的,如果你想使用更强健的持久化策略,可以考虑 Publisher Confirms。